3 Estrutura de dados e tipos de formatos
Objetivos do capítulo:
- Apresentar a distinção entre dados estruturados, dados não estruturados e dados semi estruturados
- Apresentar alguns formatos de arquivos frequentes na análise textual e humanidades digitais, como csv e tsv, Json, markdown, yaml, LaTex, BibTex, xml e html.
Podemos pensar a organização de dados quanto à sua estrutura de três formas: dados estruturados, dados semi estruturados e dados não estruturados.
3.1 Dados estruturados
Formatos de arquivos estruturados são csv,xml, json, xls, xlsx, etc. Muitos destes possuem formato de tabela, o que torna bastante fácil encontrar a informação buscada.
3.1.1 Os formatos csv (comma separeted values) e tsv.
O formato csv (comma separeted values ou “valores separados por vírgula”) é um dos mais simples, consiste de arquivo de texto simples, com valores separados por um caractere (ou conjunto de caracteres) que separam os valores em cada linha, sendo geralmente vírgula ou ponto e vírgula ou tabulação (tecla tab). Qualquer caractere ou conjunto de caracteres pode ser usado como separador de campos. Na imensa maioria dos casos cada linha é separada pela quebra de linha. Por exemplo, a seguinte tabela:
| Estado | sigla | capital | região |
|---|---|---|---|
| Acre | AC | Rio Branco | Norte |
| Alagoas | AL | Maceió | Nordeste |
| Amapá | AP | Macapá | Norte |
| Amazonas | AM | Manaus | Norte |
| Bahia | BA | Salvador | Nordeste |
| Ceará | CE | Fortaleza | Nordeste |
Em abrirmos o csv no bloco de notas (notepad):
Estado;sigla;capital;região;
Acre;AC;Rio Branco;Norte;
Alagoas;AL;Maceió;Nordeste;
Amapá;AP;Macapá;Norte;
Amazonas;AM;Manaus;Norte;
Bahia;BA;Salvador;Nordeste;
Ceará;CE;Fortaleza;Nordeste;O separador de campo neste arquivo CSV é o ponto e vírgula ;.
Ao pedirmos ao computador para localizar qual a designação da sigla “AP”, ele saberá buscar facilmente esta informação.
No caso ali, a vírgula é o separador de campos, mas qualquer outro caractere pode ser usado como separador.
O formato .tsv, por exemplo, é separado por tabulação - ou o símbolo \t.
Mas é possível encontrar arquivo csv, porém com separador tipo “ ou”;“.
3.1.2 O formato Json
O Json (“JavaScript Object Notation”, isto é “Notação de Objetos JavaScript”), é organizado no esquema de pares nome/valor.
Por exemplo, ao separarmos primeiro nome firstName de sobrenome lastName no Json:
{"employees":[
{ "firstName":"João", "lastName":"da Silva" },
{ "firstName":"Ana", "lastName":"Maria" },
{ "firstName":"Joaquim", "lastName":"Xavier" }
]}- O arquivo json inicia e termina com colchetes
[] - Todo Json é delimitado por chaves
{}, - Os dados são representados no esquema nome/valor
"nome": "valor". - Estes são separados por vírgula.
O Json tem sido muito usado nas ciência de dados como um modo leve e fácil de armazenamento de dados. É possível que ao requisitar dados em um site, ele venha em Json.
DICA: Caso queira mais detalhes sobre o formato Json:
- Video introdutório sobre o formato Json do canal Código Fonte TV JSON // Dicionário do Programador.
- Video introdutório, porém mais prático, focado na estrutura do mesmo: JSON em 6 minutos do canal “Canal TI”.
- Para ver as regras de sintaxe do Json.
3.2 Dados não estruturados
Os dados não estruturados são a forma como encontramos em livros impressos, artigos, jornais, revistas, etc. São a forma de texto que nós humanos lemos normalmente. Por exemplo:
“Algum tempo hesitei se devia abrir estas memorias pelo principio ou pelo fim, isto é, se poria em primeiro logar o meu nascimento ou a minha morte. Supposto o uso vulgar seja começar pelo nascimento, duas considerações me levaram a adoptar differente methodo: a primeira é que eu não sou propriamente um autor defunto, mas um defunto autor, para quem a campa foi outro berço; a segunda é que o escripto ficaria assim mais galante e mais novo. Moysés, que tambem contou a sua morte, não a poz no introito, mas no cabo: differença radical entre este livro e o Pentateuco….”
Este tipo de texto, não estruturado, é alvo do Processamento de linguagem natural (PLN)/ Natural Language Process (NLP).
3.3 Dados semi-estruturados
Dados semi-estruturados são um meio termo entre os estruturados e os semi estruturados. Por vezes são chamados de “auto-descritivos”. Vejamos exemplos destes.
3.3.2 O formato Markdown
Um exemplo bem simples de markup é o Markdown, usado na escrita rápida de textos.
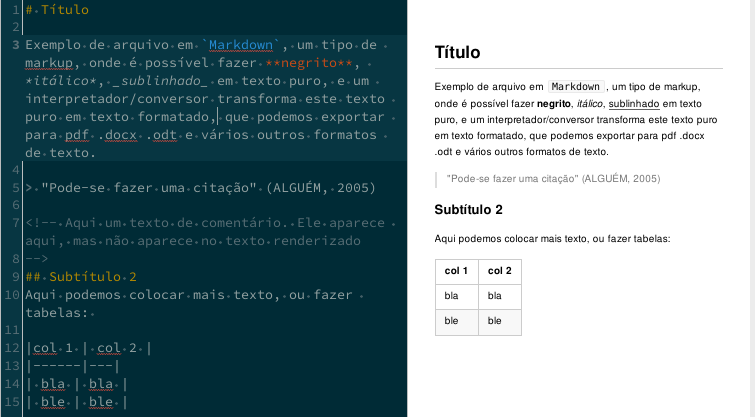
Exemplo de markdown
3.3.3 O formato YAML
O YAML (“YAML Ain’t Markup Language”) é um padrão de serialização de dados que prima por ser “human friendly”, isto é, de fácil leittura também para humanos.
Em arquivos markdown tem-se usado o yaml como cabeçalho, com informações para a renderização do pdf, como título, subtítulo, resumo, palavras chave, etc. Ao converter markdown para o formato final, o computador irá interpretar estas informações.
Um exemplo de yaml no arquivo markdown:
---
title: "Título do meu pdf"
subtitle: subtitulo qualquer
author: Fulano de Tal
# comentário qualquer
fontsize: 12pt
urlcolor: blue
geometry: margin=2.5cm
abstract: >
meu resumo bla bla bla bla
---
# Titulo
Texto texto texto texto texto texto texto
## Subtitulo
Texto texto texto texto texto texto texto O cabeçalho em yaml é delimitado no seu início e fim por três traços consecutivos ---.
Repare que o símbolo tralha # dentro do yml é interepretado como comentário, já no markdown, indica capítulo.
DICA:
Um modo prático de trabalhar na elaboração de textos - principalmente acadêmicos - com markdown e yaml é renderizá-lo com o pandoc, que é um canivete suíço na transformação de formatos de texto. Com ele, pode-se criar pdfs, html, doc, docs, odt, etc. a partir de seu arquivo markdown. Pandoc funciona via linha de comando.
3.3.4 O Formato LaTex
O LaTex é uma linguagem usada na confecção, principalmente de textos (livros, artigos) acadêmicos, bem como apresentações. O formato LaTex permite grande flexibilidade, e é muito usado para escrever fórmulas matemáticas e gerar as referências bibliográficas automaticamente. Por isso, o LaTex é muito usado no contexto acadêmico. O seu formato mínimo pode ser visto assim:
\documentclass{article}
\begin{document}
Olá Mundo
\end{document}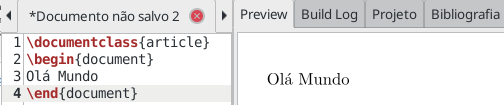
Exemplo simples de texto em LaTex e sua renderização
Ou em um exemplo um pouco mais elaborado:

Exemplo de LaTex com o software Gummi no Linux
Perceba que antes de \begin{document}, isto é, no cabeçalho do documento temos várias informações, entre elas o título do artigo na linha 5 em title{}, e em \author{}, nas linhas de 6 a 8, temos os autores. Temos também delimitados os capítulos ou seções, no caso ali em section{}.
DICA:
Para renderizar textos .tex em pdfs deve-se usar um interpretador. O pandoc é uma opção. Embora seja possível usar apenas o interpretador/conversor e um bloco de notas, o mais comum em Tex e LaTex é usar algum programa focado. O TeXstudio é uma boa opção.
Caso use Linux e queria a renderização à medida que edita o texto, olhe o Gummi.
Caso queira fazer os documentos em LaTex sem ter de “programar”, dê uma olhada no LyX.
Há também editores de LaTex online, como o overleaf, que possibilita trabalhar em equipe, observando as alterações feitas por cada pessoa
3.3.5 O formato BibTex
Um formato “irmão” do LaTex e markdown é o BibTex, um formato estruturado, com dados bibliográficos usado como fonte para gerar automaticamente a bibliografia ao final do texto renderizado em formatos como Tex, LaTex e markdown. As referências nesse formato ficam salvos num grande arquivo .bib.
Um exemplo de citação dentro do bib:
@book{Coleman:IntroMathSociology,
address = {New York},
pages = {570},
publisher = {The Free Press of Glencoe Collie, Macmillan Limited},
title = {Introduction to Mathematical Sociology},
year = {1964}
}O @book indica o tipo, podendo ser também, por exemplo, @article para artigos, @inbook para parte de um livro, @phdthesis para tese de phd (há mais opções). Para uma lista completa, ver The 14 BibTeX entry types.
O Coleman:IntroMathSociology é o ID, a identificação única, que é também usado na citação do LaTex (Por exemplo, usando \cite{Coleman:IntroMathSociology} dentro do Tex) ou do Markdown (usando [@IntroMathSociology] dentro do texto) para que o compilador saiba qual texto está sendo citado no texto. Podemos usar o texto que quisermos ali, desde que sem espaço.

Exemplo de citação usando bibtex no LaTex
Este arquivo bib que contém as referências bibliográficas, como é texto puro, pode ser editado num editor de texto comum, como o notepad, Gedit, etc. Mas o mais indicado é usar um software gestor de bibliografia, como o JabRef ou o KBibTex. O KBibTex possui menos recursos que o JabRef mas dá plenamente conta do recado, sendo inclusive o gerenciador que utilizo.
Além de ser usado para gerar pdfs com as referências, o formato também pode ser usado em pesquisas bibliométricas.
3.3.6 Os formatos xml e html
HTML, ou “Hyper Text Markup Language” é a linguagem padrão das páginas web No caso, nome seria “FirstName” e seu valor seria “João”, nome seria “lastName” e seu valor “da Silva” E esses mesmos dados no formato xml:
<employees>
<employee>
<firstName>João</firstName> <lastName>da Silva</lastName>
</employee>
<employee>
<firstName>Ana</firstName> <lastName>Maria</lastName>
</employee>
<employee>
<firstName>Joaquim</firstName> <lastName>Xavier</lastName>
</employee>
</employees>Algumas linguagens usadas em texto são chamadas de markup, onde o que é mostrado na tela, para humanos lerem, difere do que o computador “entende”. Exemplo é o xml acima, o html ou ainda linguagens como markdown e LaTex.
O html tem por base o xml. O html possui basicamente a seguinte estrutura
<!doctype html>
<html>
<head>
<title>Titulo da pagina</title>
</head>
<body>
<h1>Título do capítulo</h1>
<p>Texto texto texto</p>
</body>
</html>Se você copiar o conteúdo acima e salvar num arquivo com o nome, digamos teste.html e abrí-lo com seu navegador de internet (Firefox, Chrome, Opera, etc.), verá como funciona esta ideia de markup.
No caso do html, os valores são delimitados por tags, como: <ALGO>conteúdo</ALGO>,
onde </ indica que estamos fechando a tag. Assim, em <h1>Título do capítulo</h1>, o texto “Título do capítulo” está entre a tag “h1”.
Os arquivos html, assim como o LaTex, possui duas partes principais. O cabeçalho (head) e o corpo (body).
Figure 3.1: Tatuagem head/body. Autor desconhecido
- Entre
<head>e seu fechamento,</head>ficam os metadados, como título, data, etc. - Entre
<body>e</body>fica o conteúdo da página que aparece dentro do navegador.
Um outro exemplo:
<name>Joaquim José da Silva Xavier</name>,
o Tiradentes (<local>Fazenda do Pombal</local>,
batizado em <data>12 de novembro de 1746</data> —
<local>Rio de Janeiro</local>,
<data>21 de abril de 1792</data>),
foi um <profissao>dentista</profissao>, <profissao>tropeiro</profissao>,
<profissao>minerador</profissao>, <profissao>comerciante</profissao>,
<profissao>militar</profissao> e <profissao>ativista político</profissao> <gentilico>brasileiro</gentilico>,
que atuou nas capitanias de <local>Minas Gerais</local> e <local>Rio de Janeiro</local>.Onde podemos ver tags como <name>, <local>, <data>, etc. ao redor de certas informações, o que torna possível ao computador encontrar estas informações.
Para tutorial gratuito (em inglês) sobre html, ver W3 School.
3.3.7 Formatos mais raros
Há ainda a possibilidade de uso de estruturação de texto não muito comuns e com fins bem específicos. Por exemplo, Franzosi (2010) ao fazer análise da narrativa de jornais italianos da época de ascensão do Fascismo, passou textos não estruturados como este:
Republicans plunged in Bissone di S. Cristina around 10pm of this month at the pub Prati. A guy, who went by the name of “captain,” took out a list of names and did the roll call loudly.
Para o seguinte formato:
[Semantic triplet 1: [Participant: [Actor: republicans]] [[Process: [[Verb: plunge]
[Circumstances: [Space: [City: Bissone di S. Cristina] [[Location: pub]
[Name: Prati]]]] [[Time: [Date: 05/07/1921] [Hour: 10pm]]]]]
[Semantic triplet 2: [Participant: [Actor: captain]] [Process: [[Verb: does roll
call] [Circumstances: [Type of action: loudly] [Instrument: list]]]
[Participant: [Actor: workers]]Para tal, Franzosi desenvolveu um software para análise de narrativas textuais, o PC-ACE (Program for Computer-Assisted Coding of Events) e pôde ter uma noção melhor da violência cotidiana na época, gerado tabelas como esta:
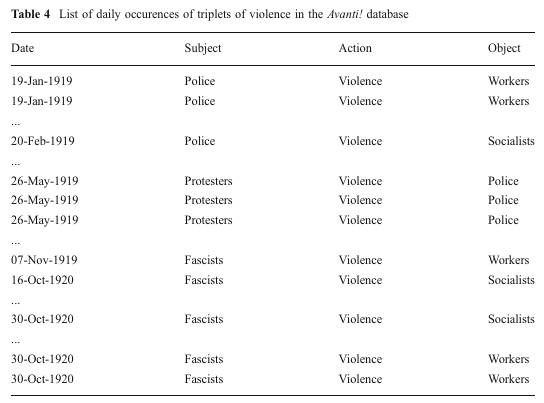
Lista da ocorrências diárias de triplets de violência, obtidas no jornal Avanti! (FRANZOSI, p.607)
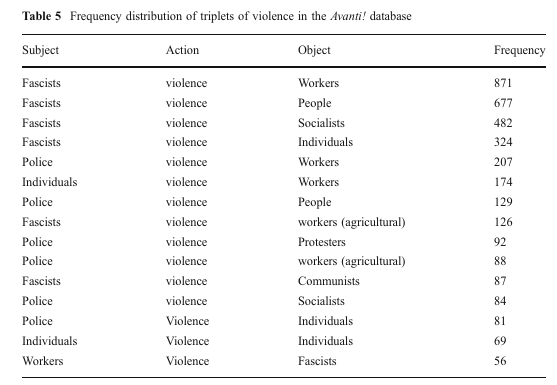
Frequência da distribuição dos triplets de violência no jornal Avanti! (FRANZOSI, p.607)
E ainda fez um “mapa de calor” (“heat map”) com a localização da violência fascista na Itália
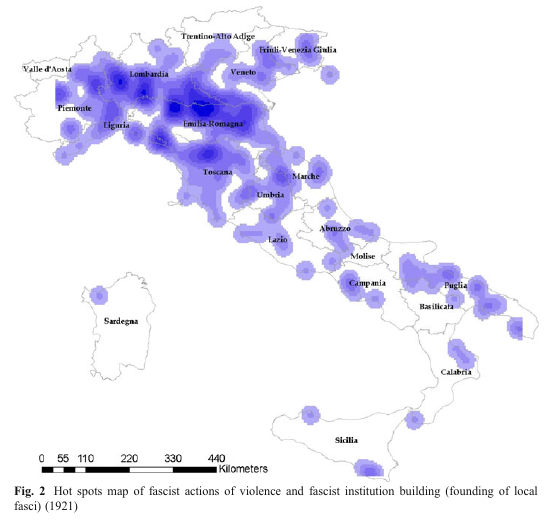
Mapa de calor de ações fascistas de violência e localização de suas sedes insittucionais (FRANZOSI, p.609)
Referência:
- FRANZOSI, Roberto P.. Sociology, narrative, and the quality versus quantity debate (Goethe versus Newton): Can computer-assisted story grammars help us understand the rise of Italian fascism (1919–1922)?. Theor Soc (2010) 39:593–629. DOI 10.1007/s11186-010-9131-3
3.4 Observações finais
Os dados semi-estruturados não tem, portanto, formato de tabela, mas contêm indicações de informações mais abstratas, através de tags ou outras marcações. Com base nestas informações que faremos análises de texto de modo computacional. Este processo de transformação de dados não estruturados em estruturados é chamado de “datificação”.
Os formatos como Json, csv, tsv, xml são importantes pois ao solicitar dados em diversos sites, muitos APIs retornam dados nestes formatos.