2 Exemplos de Pesquisas em Humanidades Digitais
Para entender os potenciais das humanidades digitais para pesquisa, nada melhor que observarmos exemplos de pesquisas. Aqui seguem alguns de exemplos, selecionados pelo potencial de integração entre humanidades e métodos digitais, mais que quanto ao possível mérito/demérito científico.
2.1 Bibliometria / cientometria / cienciometria
O estudo das citações, das rede de citações em artigos científicos foi talvez um dos pioneiros no uso de algumas das técnicas aqui descritas, existindo já há décadas. Chamada de “bibliometria”, “cientometria” ou “cienciometria”, ela conta citações de determinados autores em artigos científicos e tenta avaliar o quão influentes estes são.
2.1.1 Exemplo: Filósofos da ciência na Sociologia
Por exemplo, HEDSTRÖM et al (1998), buscando saber a influência dos principais filósofos da ciência (Hempel, Kuhn, Popper e Wittgenstein) na sociologia em diferentes países e regiões (países nórdicos, EUA, Grã Bretanha, Alemanha e França), analisou o número de artigos nas principais revistas sociológicas que os citaram.
 (Fonte: HEDSTRÖM et al. 1998. p. 343)
(Fonte: HEDSTRÖM et al. 1998. p. 343)
Pelos dados ali apresentados, Popper seria o filósofo mais influente na Europa, principalmente nos países de língua alemã, ao passo que Kuhn seria mais dominante nos EUA.
- HEDSTRÖM, Peter; SWEDBERG; and UDÉHN, Lars. Popper’s Situational Analysis and Contemporary Sociology. Philosophy of the Social Sciences 1998; 28; 339-64]
2.1.2 Exemplo: A teoria dos sistemas sociais de Niklas Luhmann
Stephen Roth analisou a chamada diferenciação funcional dos subsistemas da sociedade mundial, isto é, como os subssitemas como política, economia, religião, ciência, direito, meios de comunicação de massa, etc. se autonomizam em relação aos outros, entre os anos de 1800 e 2000, e para tal utilizou dados do Google Ngram viewer, que por sua vez se baseia no Google Books (mais detalhes sobre estas ferramentes na seção sobre frequência de palavras). Ele encontrou, por exemplo, declínio da presença relativa (isto é, proporcional a cada ano) da palavra “Deus” (god) nos livros em inglês ao longo do tempo.
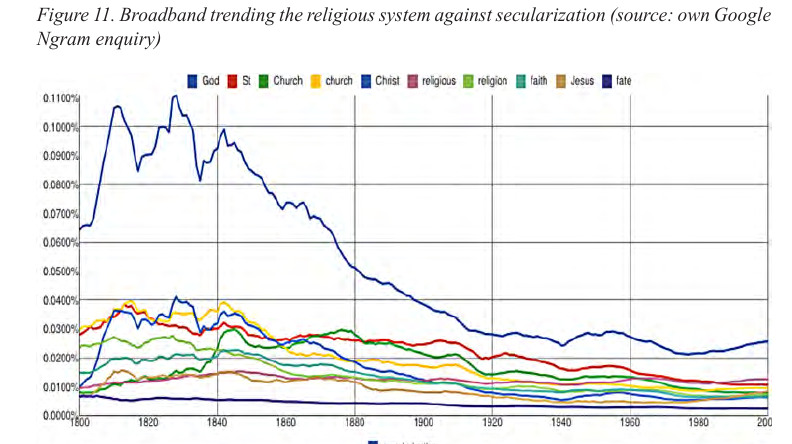
Fonte: Roth (2014, p.46).
E se examinarmos os termos relacionados aos Meios de Comunicação de Massa, podemos ver a importância relativa do termo “imprensa” (press) aumentando ao longo do tempo.
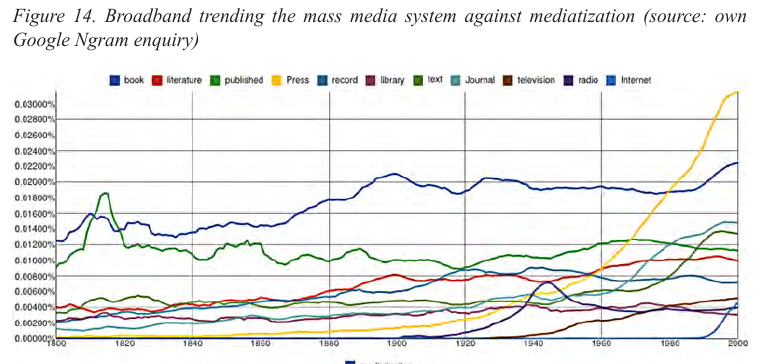
Fonte: Roth(2014, p.47).
- Roth, Steffen. 2014. “Fashionable Functions: A Google Ngram View of Trends in Functional Differentiation (1800-2000)” International Journal of Technology and Human Interaction, 34–58.
Uma versão posterior, um pouco mais elaborada em:
- Steffen Roth, Carlton Clark, Nikolay Trofimov, Artur Mkrtichyan, Markus Heidingsfelder, Laura Appignanesi, Miguel Pérez-Valls, Jan Berkel, Jari Kaivo-oja. Futures of a distributed memory. A global brain wave measurement (1800–2000). Technological Forecasting & Social Change 118 (2017) 307–323
Dicas Há o pacote no Python Get Ngrams e o R possui o pacote ngramr que pega os dados no site Google Ngram, os coloca no formato de dataframe do R, bem como plota o gráfico no R usando o pacote ggplot
- Veja a sessão dedicada ao pacote ngramr neste manual
2.1.3 Exemplo: Tendência de termos chave da Sociologia
Além de contar citação nas referências, pode-se contar as palavras mais frequentes no corpo do texto e compará-las. Bernau (2018), por exemplo, coletou dados do JSTOR’s Data for Research e plotou um gráfico longitudinal (ao longo do tempo) de frequência de palavas com termos chaves da sociologia, como “classe”, “raça” e “gênero” da revista American Sociological Review.
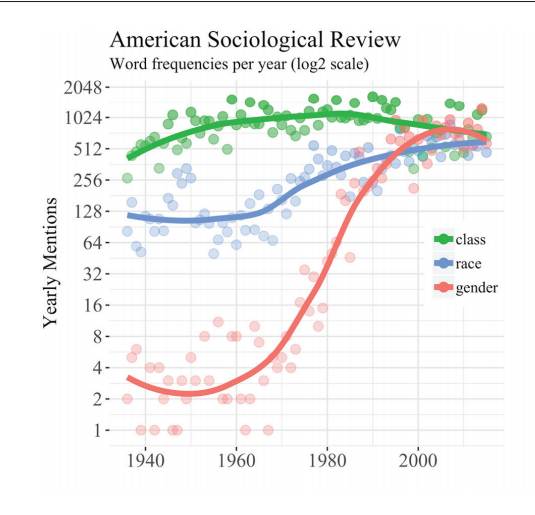
Ele também disponibilizou o script em R que desenvolveu para esta análise.
- BERNAU, John A. Text Analysis with JSTOR Archives. November 12, 2018. https://doi.org/10.1177/2378023118809264
2.1.4 Exemplo: Tendências das correntes na filosofia
Inspirado neste trabalho, Brian Weatherson usou também o pacote jstor_dfr, baixou dados da filosofia, e os clusterizou através de topic modeling. Podemos ver as tendências gerais de vários ramos da filosofia ao longo do tempo:
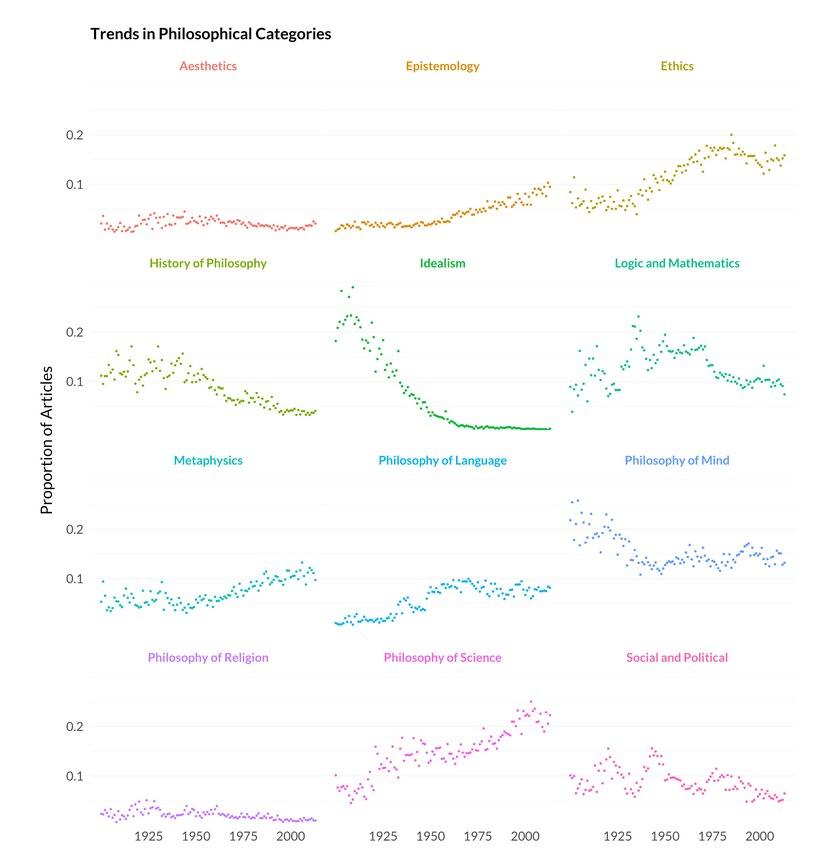
Tendencias na história da filosofia
O resultado e mais informações estão em seu livro online:
- WEATHERSON, Brian . A History of Philosophy Journals. Volume 1: Evidence from Topic Modeling, 1876-2013)
2.2 Exemplo: Google Trends como Proxy para epidemias
A busca no Google por certos sintomas de doenças, ou melhor, a variação na busca por certas doenças e sintomas correlatos pode indicar que variação real da doença. Isso acontece, por exemplo, com sintomas de gripe. Um pico no aumento das buscas pelos sintomas indica um prenúncio do aumento das infecções, a ser checado/validado posteriormente. No artigo Google Trends: A Web-Based Tool for Real-Time Surveillance of Disease Outbreaks., os autores explicam que a ferramenta lançada em 2018: > “Google Flu Trends can detect regional outbreaks of influenza 7–10 days before conventional Centers for Disease Control and Prevention surveillance systems” Para funcionar, há certas pré-condições sociais.
Vale para gripe, e a ferramenta também prevê aumentos da Covid-19. Na reportagem da Piaui “No carnaval, buscas por “sintomas covid” voltaram a subir; sete dias depois, número de novos casos bateu recorde” de 09 de março de 2021 compara as buscas no google com casos reais.
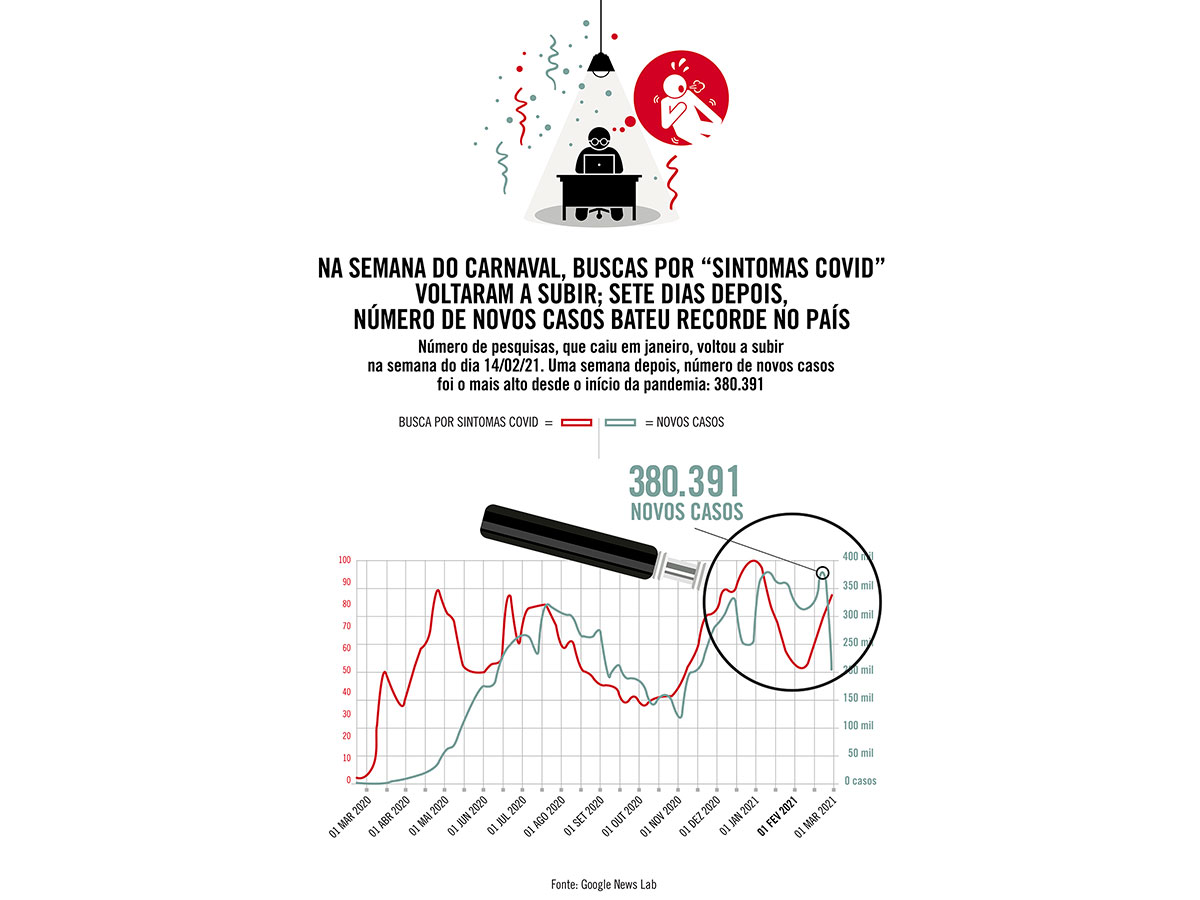
Gráfico: buscas por “sintomas Covid no Google” versus casos reais
Ver também “Sintomas Covid” en Google trends:.Un indicador alternativo para el seguimiento de la incidencia de casos. com exemplos da Espanha, México, Chile e Argentina.
No entanto, a ferramenta que parecia promissora falhou em prever o pico de gripe de 2013, sobrestimando por 140%. A empresa achou melhor terminar o projeto, conforme um artigo da Wired de 2015. Mais detalhes podem lidos no artigo The Parable of Google Flu: Traps in Big Data Analysis. O Instituto de Ciências Cognitvas de Osnabrück leva a ideia adiante, com modelo mais complexo, utilizando dados de redes sociais como Twitter e através do Watson da IBM.(site do projeto).
- O R possui o pacote gtrendsR que pega dados do Google Trends para trabalhar
2.3 Exemplo: Como as fake news sobre a pandemia de Covid-19 se assemelham/divergem entre os países?
O relatório de 23/11/2020 sobre isolamento científico, intitulado “scientific [self] isolation” do Laut, Centro de Análise da Liberdade e do Autoritarismo, cruzou as checagens de fake news de 129 países diferentes (há uma plataforma que traduz as reportagens de fact checking de todo mundo para o inglês) e investigou a distribuição de notícias falsas sobre os tratamentos da Covid19. Os pesquisadores procederam então uma distribuição num plano das discussões nos países conforme sua semelhança. Quanto mais próximos, mais semelhantes os debates ao redor do tema. Encontraram então que o Brasil é o país mais isolado em sua discussão envolvendo certos medicamentos, no canto superior direito.
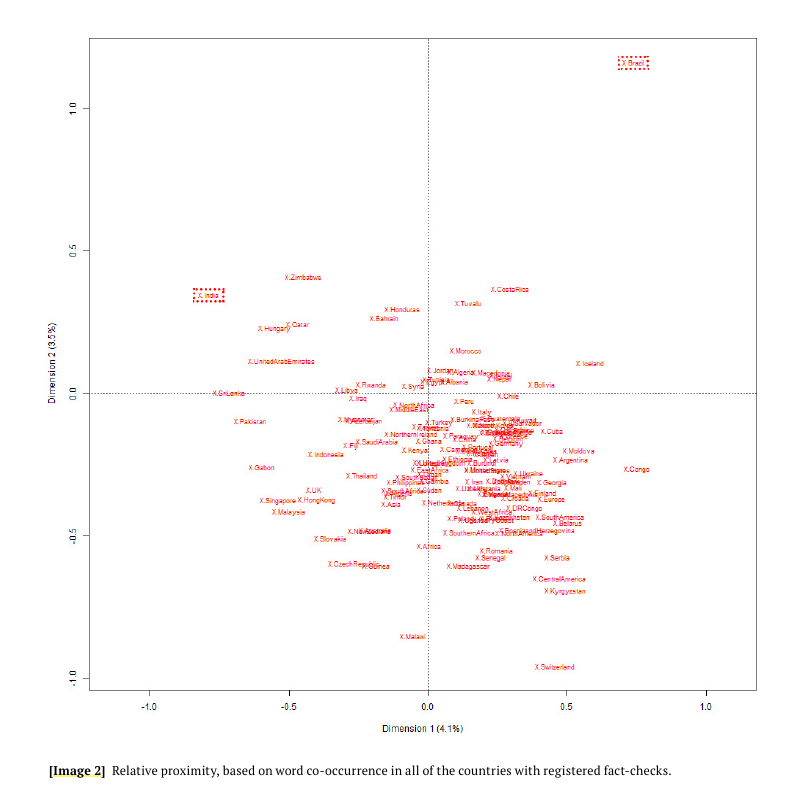
Gráfico feito com o Iramuteq
2.4 Exemplo: Mudança de significado de palavras
Kulkarni et al (2015) mostraram como através de ferramentas computacionais é possível identificar a mudança de significado de termos, seja ao longo de um século (com dados do Google NGram), seja em dinâmicas mais rápidas, como no twitter. Um dos termos analisado foi o “gay”:
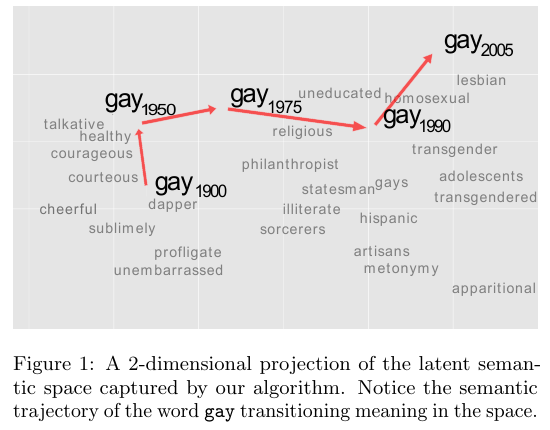
Linguistic Change da palavra “gay”
Várias outras palavras foram analisadas, como “tape” que significava “fita adesiva”, mas passou a significar também “fita cassete” nos anos 1970; ou “apple” e “windows” que ganharam novo significado com a indústria da computação.
- KULKARNI, V., Al-Rfou, R; PEROZZI, B e SKIENA, S. Statistically Significant Detection of Linguistic Change. WWW 2015, May 18–22, 2015. http://dx.doi.org/10.1145/2736277.2741627 .
2.5 Exemplo: Análise de complexidade musical
A reportagem da Folha de São Paulo Música brasileira foi simplificada ao longo das décadas, diz pesquisa cita o trabalho do cientista de dados Leonardo Sales (blog do autor), que analisou os acordes e vocabulário das letras, com base em 44 mil cifras e 102 mil letras raspadas de sites como cifras.com.br e letras.com.br em uma série de postagens: parte 1, parte 2, parte 3 sobre as letras, parte 4. Os códigos para raspagem de dados destes sites estão disponíveis em Python.
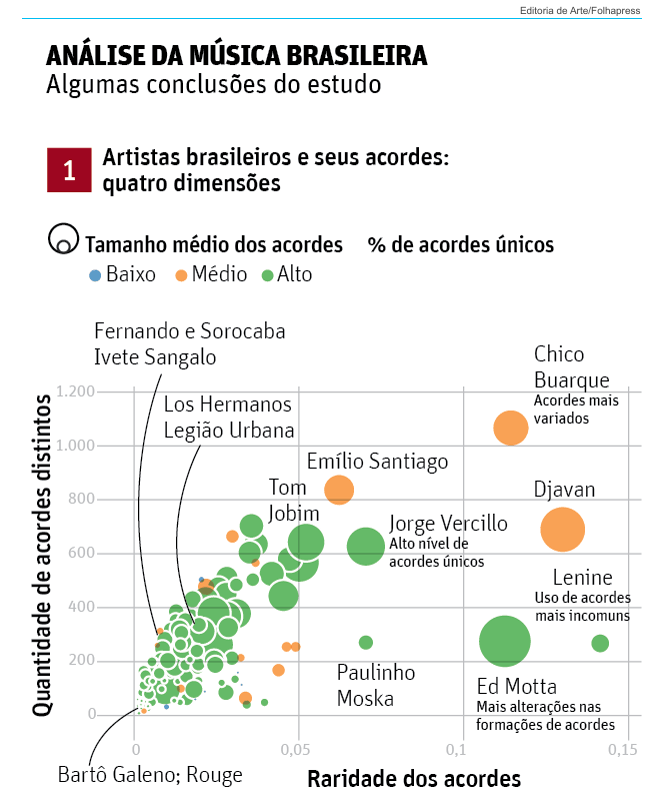
grafico
Como quase toda notação, há vantagens e desvantagens. Uma desvantagem, que levantou críticas, é que a análise se baseia em cifra, muito utilizada em músicas mais populares, mas inadequada para estilos mais complexos, como jazz.
2.6 Exemplo: Polarização
Uma boa parte de pesquisas em política com métodos digitais se dedicou a analisar o fenômeno da polarização política.
- Christopher A. Bail, Lisa P. Argyle, Taylor W. Brown, John P. Bumpus, Haohan Chen, M. B. Fallin Hunzaker, Jaemin Lee, Marcus Mann, Friedolin Merhout, and Alexander Volfovsky. 2018. Exposure to opposing views on social media can increase political polarization. Proceedings of the National Academy of Sciences 115, 37 (Sept. 2018), 9216–9221. https://doi.org/10.1073/pnas.1804840115 Publisher: National Academy of Sciences Section: Social Sciences.
Parte do trabalho de Franzosi descrevemos na seção sobre dados estruturados.
- Roberto P. Franzosi. Sociology, narrative, and the quality versus quantity debate (Goethe versus Newton): Can computer-assisted story grammars help us understand the rise of Italian fascism (1919–1922)? . Theor Soc (2010) 39:593–629 DOI 10.1007/s11186-010-9131-3
2.7 Exemplo de integração quali-quanti: Complementando dados qualitativos
Uma dica de integração quali-quanti (qualitativo e quantitativo) usando análise textual vem do PEW Research. Aqui explicam como a partir de uma análise de grupos focais feita em 2019 com grupos dos EUA e da Grã Bretanha sobre atitudes frente a globalização/nacionalismo, complementaram com pesquisa quantitativa de análise textual, analisando as diferenças entre os grupos de cada país. Usaram técnicas como frequência de palavras, correlação de palavras e Topic modelling. Através destas análises, encontraram tópicos que se mostraram relevantes a serem incorporados em surveys futuros.
- DEVLIN, Kat.“How quantitative methods can supplement a qualitative approach when working with focus groups”. medium. Dec 18, 2020.
2.8 Exemplo de integração quali-quanti: Depurando dados quantitativos
Nem sempre uma tabela de dados estruturados tem tudo estruturado, do modo que a sua pergunta de pesquisa necessite. Dentro de um campo específico de uma tabela pode-se precisar de desmembrar ainda mais os dados. Eis aqui um exemplo. Os pesquisadores do Dadoscope queriam investigar se houve aumento na abertura de igrejas evangélicas durante os anos Lula e Dilma. Os pesquisadores baixaram dados da Receita Federal referente ao Cadastro Nacional de Pessoa Jurídica e filtraram por “94.91–0–00 — Atividades de organizações religiosas ou filosóficas” no campo “Classificação Nacional de Atividades Econômicas”. O problema é que isto agrega não só igrejas evangélicas, como também católicas e de outras religiões e até agremiações filosóficas e institutos de psicanálise. Aqui entra a integração:
Para tentarmos realizar a classificação das 150 mil igrejas evangélicas de maneira semi-supervisionada nós usamos Snorkel, uma biblioteca escrita em Python… foi preciso treinar um algoritmo de classificação usando uma amostra dos dados. De forma sucinta, os dados são separados em amostras que são usadas para treino, teste e validação da classificação. Para classificar os mais de 150 mil nomes únicos presentes na amostra de treino, criamos funções que classificam de forma grosseira as igrejas (e.g., se a palavra “assembleia” estiver presente, classificar a igreja como “evangélica”). Depois de escrever dezenas dessas funções, comparamos sua acurácia com uma amostra de teste de 5% dos nomes únicos, manualmente classificados por dois pesquisadores. Feito isso, usamos uma rede neural que combina em camadas estas funções e voilá: 91.8% de acurácia. Sabemos que este resultado não é perfeito, mas ele torna o trabalho de classificação viável.
- O artigo completo “Exclusivo: Igrejas evangélicas pentecostais tiveram boom de crescimento nos governos Lula e Dilma” pode ser lido aqui: artigo na Forum e o mesmo artigo na Medium.
- Caderno de notas no dadoscope para entender melhor como o processo foi realizado.
- Sobre a ferramenta utilizada, a Snorkel, ver a página do Github, introdução (em inglês) ao Snorkel.
Por fim, outra dica para pensar a integração de dados quantitativos e qualitativos é a palestra de Dr. Christof Schöch: The Convergence of Quantitative and Qualitative Approaches, ocorrida no 1st Summerschool of Digital Humanities: Distant Reading - Potentials and Applications, em inglês.
2.9 Exemplo: Processo Civilizador
O processo civilizador é uma tese consagrada pelo sociólogo Norbert Elias, de que, ao longo dos muitos anos, séculos, haveria um longo e lento processo de diminuição da violência e da demonstração de brutalidade cotidiana, no trato do dia à dia, do aumento do sentimento de vergonha e de intimidade. Três pesquisadores tentaram ver este processo com base nos arquivos de um tribunal, analisando 11.485 julgamentos, entre 1760 e 1913.
- Klingenstein S, Hitchcock T, DeDeo S. The civilizing process in London’s Old Bailey. Proc Natl Acad Sci U S A. 2014 Jul 1;111(26):9419-24. doi: 10.1073/pnas.1405984111.
Com base nisto conseguiram observar uma tendência de longo prazo de progressiva distinção entre semântica de atos violentos e não violentos.
2.10 Ex.: Determinantes sociais do florescimento da cultura Incel
Os celibatários involuntários ou Incels, são jovens, geralmente do sexo masculino, que não tem acesso aos meios sexuais, por isso “involuntários”. De um database de nada menos que 4 bilhões de tweets (entre 2012-2018), pegaram os dados de geolocalização de 321 milhões. Filtraram 3649 tweets que usaram linguagem peculiar aos incels e 3.745 sobre incels. Com estas informações em mãos, os pesquisadores descobriram informações importantes sobre os condicionantes sociais em que floresce a cultura incel.
- Brooks RC, Russo-Batterham D, Blake KR. Incel Activity on Social Media Linked to Local Mating Ecology. Psychological Science. January 2022. doi:10.1177/09567976211036065
https://txtlab.org/2015/11/how-i-predicted-the-giller-prize/