14 Exemplo Análise - Dados da CPI da Pandemia
14.1 Introdução
Atenção: O texto a seguir não tem o intuito de ser uma análise da CPI da Pandemia, mas sim de servir de breve tutorial, de fornecer ideias de uso de algumas das ferramentas disponíveis para análise textual, que podem permitir análises posteriores mais apuradas por quem se interessar pelo tema da CPI. Utilizamos aqui a base de dados feita a partir das notas taquigráficas das reuniões da CPI da pandemia, ocorrida no ano de 2021. Confira o readme.
A primeira coisa a se fazer é colocar como opção global de nosso projeto que strings não sejam consideradas como fatores.
# Opções globais
options(stringsAsFactors = FALSE)Carregando alguns dos principais pacotes necessários. Outros serão incorporados.
library(dplyr) # para manipular os dados
library(magrittr) # para usamors os pipes: %>%
library(ggplot2) # para gerar gráficos mais agradáveisVamos importar os dados, e temos duas opções.
Opção 1: baixando a base de dados direto do site
NotasTaq <- readRDS(url("https://github.com/SoaresAlisson/NotasTaquigraficas/raw/master/rds/NT_todas_normalizado.rds"))Opção 2: utilizando arquivo no seu computador.
É possível também baixar a base de dados em seu computador e carregá-la dali.
Para tal, 1) baixe o aquivo pelo site e salve em seu computador; 2) copie o endereço do arquivo no seu computador 3) Use a função readRDS() com o endereço do arquivo, como no exemplo abaixo.
Ali utiliza-se um endereço padrão Linux. Caso utilize Windows, o caminho para o arquivo pode ser que tenha que ser algo como readRDS("c:/
NotasTaq <- readRDS("~/Documentos/Programação/R/NotasTaquigraficas/NT_todas_normalizado.rds")
NotasTaq <- readRDS("~/Documentos/Programacao/R/NotasTaquigraficas/NT_todas_normalizado.rds")Vamos transformar nosso dataframe em tibble, caso ainda não o seja
NotasTaq <- as_tibble(NotasTaq)
# conferindo se é tibble
class(NotasTaq)
## [1] "tbl_df" "tbl" "data.frame"
# "tbl_df" indica que é tibble
# observando a estrutura de nossa tabela
str(NotasTaq)
## tibble [94,272 × 9] (S3: tbl_df/tbl/data.frame)
## $ reuniao : num [1:94272] 1 1 1 1 1 1 1 1 1 1 ...
## $ data : Date[1:94272], format: "2021-04-27" "2021-04-27" ...
## $ nome : chr [1:94272] "Otto Alencar" "Ciro Nogueira" "Otto Alencar" "Ciro Nogueira" ...
## $ funcao_blocoPar: chr [1:94272] "PRESIDENTE" "(Bloco Parlamentar Unidos pelo Brasil/PP - PI. Para questão de ordem.)" "PRESIDENTE" "(Bloco Parlamentar Unidos pelo Brasil/PP - PI)" ...
## $ BlocoParl : chr [1:94272] "(Otto Alencar. PSD - BA. Fala da Presidência.)" "Bloco Parlamentar Unidos pelo Brasil" "(Otto Alencar. PSD - BA)" "Bloco Parlamentar Unidos pelo Brasil" ...
## $ partido : Named chr [1:94272] "PSD" "PP" "PSD" "PP" ...
## ..- attr(*, "names")= chr [1:94272] "PSD" "PP" "PSD" "PP" ...
## $ estado : chr [1:94272] "BA" "PI" "BA" "PI" ...
## $ complemento : chr [1:94272] "Fala da Presidência" "Para questão de ordem" "" "" ...
## $ fala : chr [1:94272] "Invocando a proteção de Deus, declaro aberta a sessão para eleição, já que temos quórum suficiente para a abert"| __truncated__ "Sr. Presidente, Sras. e Srs. Senadores, eu achava que nós deveríamos suspender a atual sessão até que seja sana"| __truncated__ "Senador Ciro Nogueira, esta é uma Comissão Parlamentar de Inquérito, V. Exa. sabe que não é temática. Então, é "| __truncated__ "Sr. Presidente, não é o caso de indeferir ou não. Isso aqui... " ...Vemos que a coluna “BlocoParl” foi desmembrada em outras, como “partido”, “estado” e “complemento”, o que facilita se quisermos filtrar por estas variáveis.
Se quisermos dar uma olhada na tabela completa, usamos a função View().
View(NotasTaq)14.2 Pré-processamento
O pré-processamento de texto é necessário para evitar certas dores de cabeça mediante a padronização dos dados.
14.2.1 Pré-processamento: substituição de abreviaturas
Nosso primeiro passo no pré-processamento será substituir as abreviaturas mais comuns pelo seu equivalente por extenso. Vamos pegar abreviaturas usando um regex, pegando qualquer palavra que se inicie com maiúsculo e que termine com ponto final. Talvez este não seja o melhor regex para este caso, e teremos vários “falsos positivos”, mas será melhor que buscá-las manualmente, uma a uma lendo todo o texto (precisaríamos de dias para tal). Dali, observamos e montamos nossa tabela de abreviaturas.
abrev <- stringr::str_extract_all(NotasTaq$fala,
"([A-Z][a-z]{0,4}\\. )?([A-Z]+|[A-Z][a-z]{0,4})\\.") |>
unlist() |> sort()
abrev_cont <- abrev |>
# contando com plyr::count temos um dataframe com a frequencia
plyr::count() |>
arrange(desc(freq))
# Vamos observar os termos com maior frequência
head(abrev_cont, 50)
## x freq
## 1 Sr. 12227
## 2 V. Exa. 7453
## 3 V. Sa. 4444
## 4 Dr. 1917
## 5 Dra. 1321
## 6 Sim. 1263
## 7 CPI. 1247
## 8 O. 785
## 9 Srs. 773
## 10 Sra. 720
## 11 Sras. 469
## 12 Isso. 392
## 13 Renan. 379
## 14 Covid. 345
## 15 Paulo. 205
## 16 Dias. 201
## 17 Risos. 197
## 18 S. Exa. 183
## 19 V. Exas. 174
## 20 Claro. 159
## 21 Certo. 157
## 22 Costa. 133
## 23 Bank. 127
## 24 Omar. 127
## 25 Log. 122
## 26 Otto. 115
## 27 China. 105
## 28 S. 105
## 29 Aziz. 103
## 30 Vac. 101
## 31 Braga. 93
## 32 Penal. 88
## 33 Sul. 87
## 34 SUS. 79
## 35 CGU. 76
## 36 Casa. 73
## 37 Ltda. 73
## 38 Tebet. 73
## 39 UTI. 73
## 40 Leila. 72
## 41 Exato. 67
## 42 Eu. 63
## 43 V. 60
## 44 Art. 58
## 45 D. 55
## 46 Secom. 54
## 47 Val. 53
## 48 Nunca. 52
## 49 Mello. 51
## 50 Deus. 50Podemos obter a frequência usando o comando table, mas ao usarmos plyr::count temos mais facilidades, uma vez que temos um dataframe.
Criando um dataframe com termos a serem substituídos. header = true indica que a primeira linha será o cabeçalho, sep="":" indica que usarmos o caracter dois pontos para separa as colunas.
D.subs <- read.table(header=TRUE, sep = ":", text=
'abr:subs
app.:aplicativo
Art.:artigo
Cel.:coronel
Dr.:Doutor
Dra.:doutora
Drs.:doutores
Exma.|Ex.ma.:excelentíssima
Exmo.|Ex.mo.:excelentíssimo
Gen.:general
Jr.:Júnior
Mr.:mister
Sgt.:sargento
Sr.:senhor
Sra.:senhora
Sras.:senhoras
Srta.:senhorita
Srs.:senhores
S. Exa.:Sua_Excelência
V. Exa.:vossa_excelência') |>
# para repassar múltiplos argumentos para uma mesma string
# precisamos converter o dataframe para vetor nomeado
tibble::deframe()
# vamos agora substituir as abreviações no dataframe
NotasTaq <- NotasTaq |>
mutate(fala = stringr::str_replace_all(fala, D.subs))Se quisermos olhar os termos no contexto, isto é, as palaras que o circundam, para nos certificarmos que se trata realmente de abreviações, podemos usar o seguinte código, no suposto de que: - abreviaturas terminam com ponto final -
termo="Val"
termo="Art"
stringr::str_extract(NotasTaq$fala, paste0("(\\w+.){2}", termo, "\\..\\w+")) |> table()
## < table of extent 0 >14.2.2 Primeiras observações
Vamos observar os nomes das pessoas que falaram na CPI:
participantes <- NotasTaq$nome |> unique()
# contando os participantes
length(participantes)
## [1] 153
# vendo os nomes dos participantes, em ordem alfabética
sort(participantes)
## [1] "Airton Antonio Soligo"
## [2] "Alan Diniz Moreira Guedes de Ornelas"
## [3] "Alberto Zacharias Toron"
## [4] "Alessandro Vieira"
## [5] "Alexandre Figueiredo Costa Silva Marques"
## [6] "Alexandre Queiroz"
## [7] "Amilton Gomes de Paula"
## [8] "Andreia da Silva Lima"
## [9] "Angelo Coronel"
## [10] "Antonio Barra Torres"
## [11] "Antonio Carlos Alves de Sá Costa"
## [12] "Antônio Elcio Franco Filho"
## [13] "Antonio Manssur"
## [14] "Aristides Zacarelli"
## [15] "Arquivaldo Bites Leão Leite"
## [16] "Beno Brandão"
## [17] "Bia Kicis"
## [18] "Bruna Mendes dos Santos Morato"
## [19] "Carlos Murillo"
## [20] "Carlos Portinho"
## [21] "Carlos Roberto Wizard Martins"
## [22] "Ciro Nogueira"
## [23] "Cláudio Maierovitch"
## [24] "Cleber Lopes de Oliveira"
## [25] "Cristiano Alberto Hossri Carvalho"
## [26] "Daniel Freitas"
## [27] "Daniel Sampaio"
## [28] "Daniella Ribeiro"
## [29] "Danilo Berndt Trento"
## [30] "Dimas Tadeu Covas"
## [31] "Eduardo Braga"
## [32] "Eduardo de Vilhena Toledo"
## [33] "Eduardo Girão"
## [34] "Eduardo Pazuello"
## [35] "Eliana Maria dias Santiago"
## [36] "Eliane Nogueira"
## [37] "Eliziane Gama"
## [38] "Elton da Silva Chaves"
## [39] "Emanuel Ramalho Catori"
## [40] "Emanuela Batista de Souza Medrades"
## [41] "Emerson Paxá Pinto Oliveira"
## [42] "Eric Furtado Ferreira Borges"
## [43] "Ernesto Araújo"
## [44] "Fabiano Contarato"
## [45] "Fábio Henrique Ming Martini"
## [46] "Fabio Wajngarten"
## [47] "Fausto Vieira dos Santos Junior"
## [48] "Felipe Dantas de Araujo"
## [49] "Fernando Bezerra Coelho"
## [50] "Flávio Bolsonaro"
## [51] "Flavio Correa de Moraes"
## [52] "Francieli Fontana Sutile Fantinato"
## [53] "Francieli Fontana Sutile Tardetti Fantinato"
## [54] "Francisco Araújo Filho"
## [55] "Francisco Eduardo Cardoso Alves"
## [56] "Francisco Emerson Maximiano"
## [57] "Gina Moraes de Almeida"
## [58] "Giordano"
## [59] "Giovanna Gomes Mendes da Silva"
## [60] "Guilherme Cremonesi Caurin"
## [61] "Helcio Bruno de Almeida"
## [62] "Humberto Costa"
## [63] "Ivanildo Gonçalves da Silva"
## [64] "Izalci Lucas"
## [65] "Jailton Batista"
## [66] "Jean Paul Prates"
## [67] "João Carlos Gonçalves Krakauer Maia"
## [68] "Jorge Kajuru"
## [69] "Jorginho Mello"
## [70] "José Ricardo Santana"
## [71] "Jurema Werneck"
## [72] "Kátia Abreu"
## [73] "Katia Shirlene Castilho dos Santos"
## [74] "Leila Barros"
## [75] "Luana Araújo"
## [76] "Luciano Duarte Peres"
## [77] "Luciano Hang"
## [78] "Luis Carlos Heinze"
## [79] "Luis Miranda"
## [80] "Luis Ricardo Fernandes Miranda"
## [81] "Luiz Henrique Mandetta"
## [82] "Luiz Paulo Dominguetti Pereira"
## [83] "Mara Gabrilli"
## [84] "Marcellus Campelo"
## [85] "Marcellus José Barroso Campêlo"
## [86] "Marcelo Antônio Cartaxo Queiroga Lopes"
## [87] "Marcelo Blanco"
## [88] "Marcelo Blanco da Costa"
## [89] "Marcelo Queiroga"
## [90] "Márcio Antonio do Nascimento Silva"
## [91] "Marconny Nunes Ribeiro Albernaz de Faria"
## [92] "Marcos do Val"
## [93] "Marcos Rogério"
## [94] "Marcos Tolentino da Silva"
## [95] "Maria Jamile José"
## [96] "Maria José Ferreira Pessoa"
## [97] "Mayra Pinheiro"
## [98] "Mayra Pires Lima"
## [99] "Mecias de Jesus"
## [100] "Michel Saliba Oliveira"
## [101] "Milena Ramos Câmara"
## [102] "Natalia Pasternak"
## [103] "Nelsinho Trad"
## [104] "Nelson Luiz Sperle Teich"
## [105] "Nise Hitomi Yamaguchi"
## [106] "Omar Aziz"
## [107] "Osmar Terra"
## [108] "Otávio de Queiroga"
## [109] "Otávio Oscar Fakhoury"
## [110] "Otto Alencar"
## [111] "Paulo Roberto Vanderlei Rebello Filho"
## [112] "Paulo Rocha"
## [113] "Pedro Benedito Batista Júnior"
## [114] "Pedro Hallal"
## [115] "Pedro Henrique Medeiros de Araújo"
## [116] "Pedro Ivo Velloso"
## [117] "Priscila Pamela Cesario dos Santos"
## [118] "Raimundo Nonato Brasil"
## [119] "Randolfe Rodrigues"
## [120] "Regina Célia Silva Oliveira"
## [121] "Reguffe"
## [122] "Reinhold Stephanes Junior"
## [123] "Renan Calheiros"
## [124] "Ricardo Ariel Zimerman"
## [125] "Ricardo Barros"
## [126] "Roberto Ferreira dias"
## [127] "Roberto Pereira Ramos Júnior"
## [128] "Roberto Rocha"
## [129] "Rodrigo Cunha"
## [130] "Rogério Carvalho"
## [131] "Rosane Maria dos Santos Brandão"
## [132] "Rose de Freitas"
## [133] "Savio de Faria Caram Zuquim"
## [134] "Simone Tebet"
## [135] "Soraya Thronicke"
## [136] "Styvenson Valentim"
## [137] "Tadeu Frederico de Andrade"
## [138] "Tasso Jereissati"
## [139] "Telmário Mota"
## [140] "Thiago Leônidas"
## [141] "Ticiano Figueiredo"
## [142] "Ticiano Figueiredo de Oliveira"
## [143] "Túlio Silveira"
## [144] "Vanderlan Cardoso"
## [145] "Vinicius Luiz Ferreira"
## [146] "Wagner de Campos Rosário"
## [147] "Wagner Lima da Costa"
## [148] "Walter Correa de Souza Neto"
## [149] "Walter José Faiad de Moura"
## [150] "Weverton"
## [151] "William Amorim Santana"
## [152] "Wilson Witzel"
## [153] "Zenaide Maia"Numa primeira observação, vamos ver a quantidade de intervenções de cada pessoa, isto é, quantas vezes uma pessoa iniciou uma fala, independente da quantidade de palavras ditas. Para tal, vamos fazer um gráfico de barras com o barplot do pacote base, que já vem por padrão no R:
# Para usar o barplot, precisamos antes converter para table
intervencoes <- NotasTaq$nome %>% table
intervencoes %>%
barplot(.,
main="Quantidade de Intervenções", # titulo
ylab="Frequência", # eixo y
cex.lab=1, # tamanho do label
cex.axis=0.1, # tamanho do texto nos eixos
cex.names=0.5, # tamanho dos nomes eixo x
las=2 # rotacionando
)
Podemos usar o ggplot e termos mais opções de controle.
Se formos olhar a frequência das cerca de 150 pessoas, teremos um gráfico não muito compreensível:
ggplot(data = NotasTaq,
aes(x = nome, y = )) +
geom_bar() +
labs(title = "Quantidade de intervenções", x = "",y = "") +
theme(axis.text.x = element_text(angle = 90))
Vamos melhorar este gráfico restringindo apenas aos casos mais frequentes e rotacionando seu eixo.
# criando um novo dataframe com nomes e contagem
intervencoes <- NotasTaq$nome %>% plyr::count()
# renomeando as colunas
colnames(intervencoes) <- c("nome","freq")
# Ordenando pela coluna "freq" de modo decrescente.
dplyr::arrange(intervencoes, desc(freq)) %>%
# restringindo aos 30 mais frequentes
head(30) %>%
ggplot( aes(x = reorder(nome, freq), y = freq)) +
geom_col() +
labs(title = "Quantidade de intervenções na CPI", x = "",y = "") +
theme(axis.text.x = element_text(angle = 90)) +
# girando o gráfico
coord_flip() 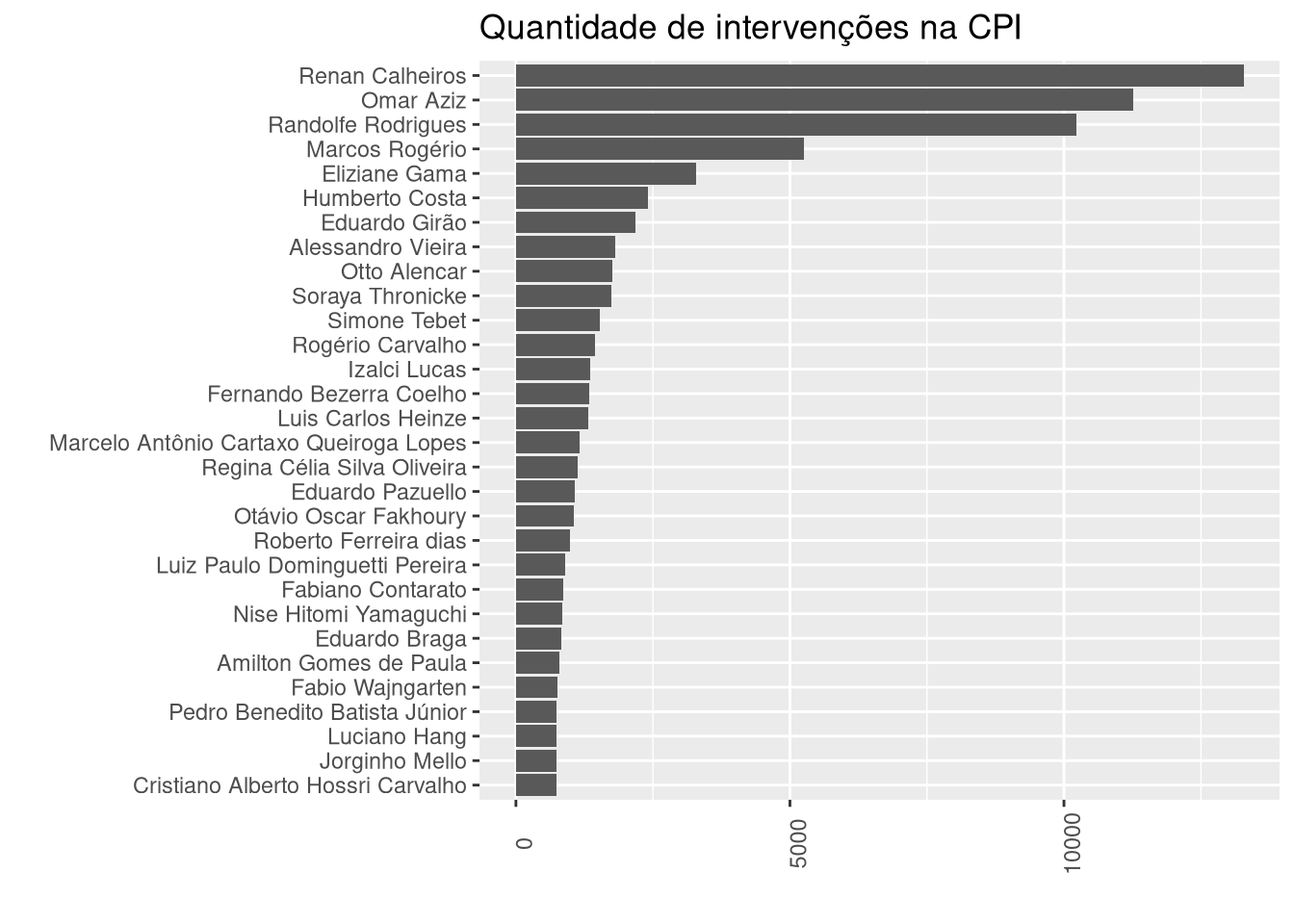
- Para contar as intervenções pode-se usar o
table- como usamos para gerar o barplot anterior - mas uma opção mais prática é usar oplyr::count(), que nos retorna um dataframe, o que torna mais fácil lidar com dados gerados. - Apesar de termos ordenado nossos dados com base na frequência, o ggplot organiza os dados com base na ordem alfabética dos nomes. Mas se quisermos organizar na ordem das intervenções, usamos
aes(x = reorder(eixoX, eixoY), y = eixoY))ou no casoaes(x = reorder(nome, freq), y = freq)).
O resultado do gráfico faz todo o sentido, entre os nomes mais frequentes estarem o depoente, o presidente e relator.
Vamos ver agora o ranking por quantidade de palavras ditas.
Vamos utilizar números mais gerais dos parlamentares, referentes à todas as sessões. Para tal, vamos agregar as falas de diferentes dias em uma linha por nome através dos comandos do dplyr group_by e summarize, e como o que queremos é que junte todas as falas em uma só célula, vamos usar de paste() com o parâmetro collapse = " " que indica que entre uma fala e outra que serão condensadas em uma só célula, entre cada elemento será inserido um espaço vazio, para evitar que uma palavra final de uma célula fique colada à palavra inicial da célula seguinte.
NotasTaq_falas.agrupadas <- NotasTaq %>%
group_by(nome) %>%
summarize(falas = paste(fala, collapse = " "))
# se quisermos observar a estrutura de nosso dataframe
str(NotasTaq_falas.agrupadas)
## tibble [153 × 2] (S3: tbl_df/tbl/data.frame)
## $ nome : chr [1:153] "Airton Antonio Soligo" "Alan Diniz Moreira Guedes de Ornelas" "Alberto Zacharias Toron" "Alessandro Vieira" ...
## $ falas: chr [1:153] "senhor Presidente, acredito que, em função da decisão, eu não sou obrigado, mas estou aqui para dizer a verdade"| __truncated__ "Presidente, só uma questão de ordem então? Para deixar o registro, então, de que, com a liminar do STF, do Min"| __truncated__ "Perfeitamente, Excelência, senhor Presidente em exercício. senhor Presidente, o despacho, se vossa_excelência "| __truncated__ "Pela ordem, Presidente Otto Alencar. senhor Presidente... Obrigado, senhor Presidente. Apenas quero contradit"| __truncated__ ...
# contando as palavras
NT_falasJuntasCount <- NotasTaq_falas.agrupadas %>%
mutate(N_palavras = stringr::str_count(falas, "\\W"),
.after = 1) |>
# reordenar pelo número de palavras (arrange) dos maiores valores aos menores (desc)
arrange(desc(N_palavras))
# plotando o gráfico
NT_falasJuntasCount %>%
# restringindo aos primeiros resultados
head(30) %>%
ggplot( aes(x = reorder(nome, N_palavras), y = N_palavras)) +
geom_col() +
labs(title = "Quantidade de palavras ditas na CPI", x = "",y = "") +
theme(axis.text.x = element_text(angle = 90)) +
# girando o gráfico
coord_flip() 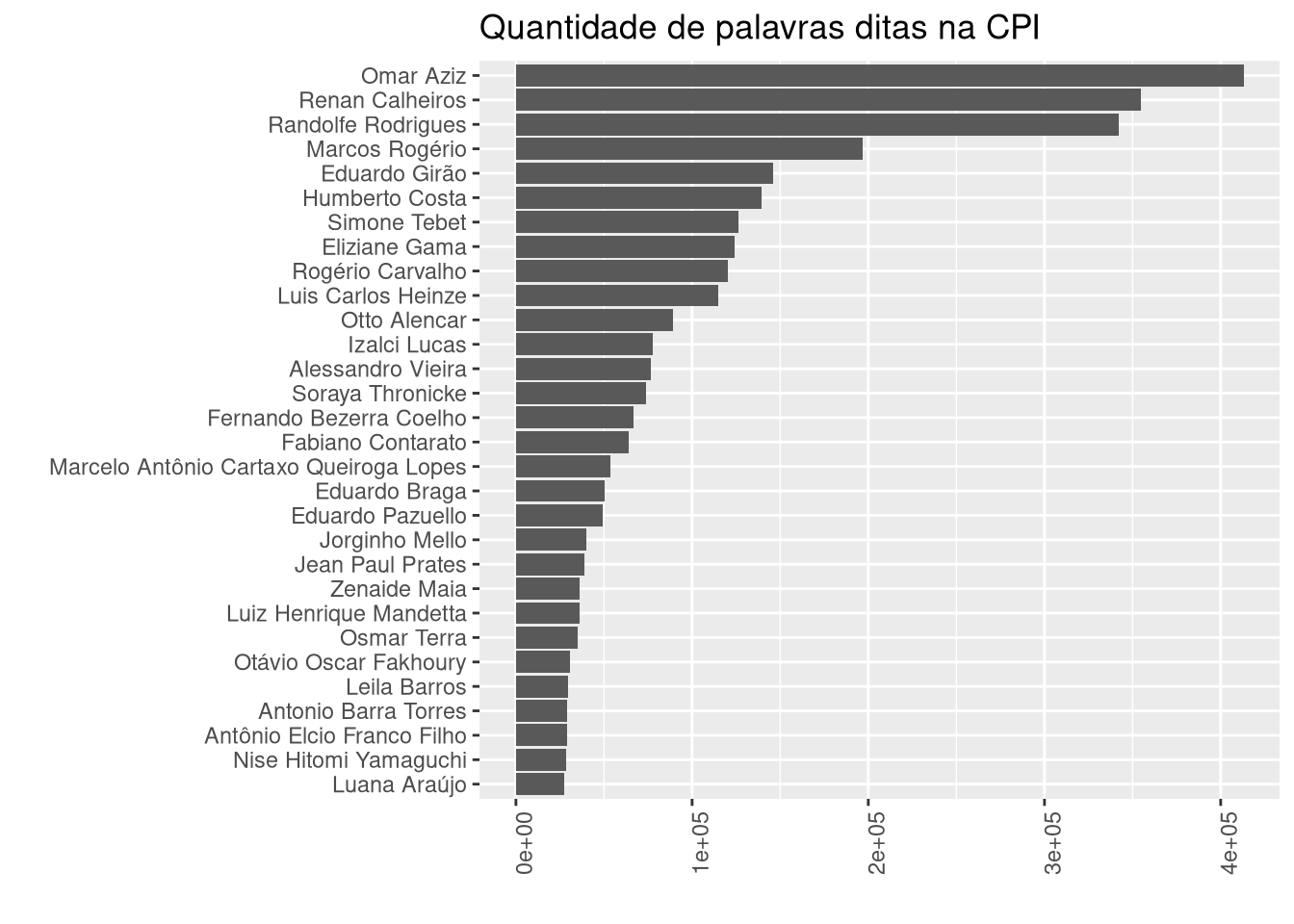
14.3 Entes
Dado que o texto das notas taquigráficas possuem certa formalização, um modo simples de pegar nomes próprios - não dos mais eficientes, é verdade, mas relativamente rápido - é utilizando regex. Um dos principais problemas de usar regex neste caso, é que este padrão irá pegar também palavras em maiúsculo que iniciam frases, teremos vários falsos positivos. Esta ferramenta, portanto, pode servir apenas como um auxílio na exploração do texto.
# Todas palavras únicas em maiúsculo
entes1 <- NT_falasJuntasCount$falas |>
stringr::str_extract_all("([A-ZÀ-ÿ][a-zà-ÿ\\-]+)")
# Palavras em maiúsculo, com duas ou mais palavras em maiúsculo
entes <- NT_falasJuntasCount$falas |>
stringr::str_extract_all("([A-ZÀ-ÿ][a-zà-ÿ\\-]+ (d[aeo]s? )?){2,}([A-ZÀ-ÿ][a-zà-ÿ\\-])*" )
entes1 <- entes1[[3]] |> stringr::str_trim(side = "both") |> unique() |> sort()
entes <- entes[[3]] |> stringr::str_trim(side = "both") |> unique() |> sort()
# Dando uma olhada
head(entes1, 30)
## [1] "A-" "á-fé" "á-la" "á-las"
## [5] "á-lo" "á-los" "ábado" "Abaixe"
## [9] "Abaixo" "Abastecimento" "Abbott" "Abdul"
## [13] "Aberto" "ábil" "Abin" "ábito"
## [17] "Abraão" "Abre" "Abreu" "ábricas"
## [21] "Abril" "Abro" "Abs" "Absolutamente"
## [25] "Abuso" "Acaba" "Acabamos" "Acabei"
## [29] "Acabou" "Academia"
head(entes, 30)
## [1] "Abdul Fares"
## [2] "Academia Militar das Agulhas Ne"
## [3] "ácia da Annita"
## [4] "ácia de João Do"
## [5] "Acima do Doutor Lauricio"
## [6] "Adolf Eichmann"
## [7] "Advirto às"
## [8] "Advocacia da União"
## [9] "Advocacia do Senado"
## [10] "Advogado da União"
## [11] "ãe da Katia"
## [12] "áfico da Barão Tu"
## [13] "áficos do Ministério da Saúde"
## [14] "Agência Bradesco"
## [15] "Agência Bradesco do"
## [16] "Agência Brasileira de Inteligência"
## [17] "Agência de Vigilância Sanitária"
## [18] "Agência Lupa"
## [19] "Agência Nacional de Saúd"
## [20] "Agência Nacional de Saúde"
## [21] "Agência Nacional de Saúde Complementar"
## [22] "Agência Nacional de Saúde Su"
## [23] "Agência Nacional de Vigilância Sa"
## [24] "Agência Nacional de Vigilância Sanitária"
## [25] "Agência Senado"
## [26] "ágina da Comissão Parlamentar de In"
## [27] "áginas do Instituto Força Br"
## [28] "ágrafo único do Código de Processo Pe"
## [29] "água Lavem"
## [30] "Airton Soligo"14.4 Palavras chave em contexto - KWIC
Para entender melhor como certas palavras foram utilizadas, em que contexto elas apareceram, podemos utilizar o Keywords in context
# Carregando o pacote
library(quanteda)
# Transformando o dataframe em corpus do quanteda
Corpus.NT.falas.agrupadas <- corpus(NotasTaq_falas.agrupadas,
docnames = "nome",
# docid_field = 1:nrow(NotasTaq_falas.agrupadas),
docid_field = "nome",
text_field = "falas" )
## Warning: docnames argument is not used.
# observando nosso corpus
print(Corpus.NT.falas.agrupadas)
## Corpus consisting of 153 documents.
## Airton Antonio Soligo :
## "senhor Presidente, acredito que, em função da decisão, eu nã..."
##
## Alan Diniz Moreira Guedes de Ornelas :
## "Presidente, só uma questão de ordem então? Para deixar o re..."
##
## Alberto Zacharias Toron :
## "Perfeitamente, Excelência, senhor Presidente em exercício. ..."
##
## Alessandro Vieira :
## "Pela ordem, Presidente Otto Alencar. senhor Presidente... ..."
##
## Alexandre Figueiredo Costa Silva Marques :
## "Senador, eu vou me valer do habeas corpus que me foi deferid..."
##
## Alexandre Queiroz :
## "Presidente, bom dia. Bom dia, eminente Relator, senhors. Se..."
##
## [ reached max_ndoc ... 147 more documents ]
summary(Corpus.NT.falas.agrupadas, 5)
## Corpus consisting of 153 documents, showing 5 documents:
##
## Text Types Tokens Sentences
## Airton Antonio Soligo 2706 19501 1367
## Alan Diniz Moreira Guedes de Ornelas 238 632 60
## Alberto Zacharias Toron 233 632 55
## Alessandro Vieira 6976 73630 3955
## Alexandre Figueiredo Costa Silva Marques 1323 7169 459
# tokenizando para poder usar no kwic
corpus.token <- Corpus.NT.falas.agrupadas |>
# precisamos primeiro tokenizar
tokens()
# termos a serem buscados
termos.vetor <- c("WhatsApps", "Quickcard")
# rodando a função de palavras chave em contexto
kwic(corpus.token ,
# termos a serem buscados. Pode ser um termo ou um vetor
termos.vetor,
# quantas palavras devem ser mostradas ao redor
4,
# Para pegar tanto palavras minúsculas como as em maiúsculo.
case_insensitive = TRUE)
## Keyword-in-context with 10 matches.
## [Humberto Costa, 18096] já recebi hoje alguns | WhatsApps |
## [Humberto Costa, 36777] , vários telefonemas e | WhatsApps |
## [Jean Paul Prates, 12712] conhece um serviço chamado | QuickCard |
## [Jean Paul Prates, 12714] serviço chamado QuickCard? | QuickCard |
## [Jean Paul Prates, 12727] . Você emite um | QuickCard |
## [Jean Paul Prates, 12760] para esse serviço chamado | QuickCard |
## [Jean Paul Prates, 12997] é o pagamento à | QuickCard |
## [Jean Paul Prates, 13014] adiante: a quem | QuickCard |
## [Randolfe Rodrigues, 210993] Abdul, vamos aos | WhatsApps |
## [Randolfe Rodrigues, 211147] Pode continuar com os | WhatsApps |
##
## e tal. O
## de assessores do ministério
## ? QuickCard é uma
## é uma espécie de
## para alguém e essa
## . O senhor tem
## . O que a
## pagou, ou quem
## . O senhor Abdul
## . Pode continuar,Vamos colocar os gráficos lado a lado para facilitar a comparação. Para tal, vamos utilizar o pacote patchwork que torna bem fácil colocar múltiplos gráficos juntos, nas mais diferentes configurações de layout. Para usá-lo, vamos primeiro salvar os gráficos como objetos R e depois vamos organizá-los no patchwork. Os gráficos são os mesmos que usamos mais acima.
Para instalar, podemos usar o comando install.packages('patchwork').
# carregando o pacote
library(patchwork)# Número de corte do máximo de itens a aparecer no gráfico
n <- 20
graf1 <- dplyr::arrange(intervencoes, desc(freq)) %>%
# restringindo aos 30 mais frequentes
head(n) %>%
ggplot( aes(x = reorder(nome, freq), y = freq)) +
geom_col() +
labs(title = "intervenções", x = "",y = "") +
theme(axis.text.x = element_text(angle = 90),
# diminuindo a letra do título do gráfico
plot.title = element_text(size=9)) +
# girando o gráfico
coord_flip()
graf2 <- NT_falasJuntasCount %>%
# restringindo aos primeiros resultados
head(n) %>%
ggplot( aes(x = reorder(nome, N_palavras), y = N_palavras)) +
geom_col() +
labs(title = "palavras ditas", x = "",y = "") +
theme(axis.text.x = element_text(angle = 90),
# diminuindo o tamanho do título do gráfico
plot.title = element_text(size=9)) +
# girando o gráfico
coord_flip()
# usando o patchwork pra colocar os gráficos lado a lado
graf1 + graf2 +
# adicionando titulo ao gráfico
plot_annotation(title = 'CPI da Pandemia: falas quantificadas de todas as reuniões',
subtitle = "Número de intervenções (esquerda) vs. quandidade de palavras ditas (direita)",
caption = '*Apenas os 20 mais frequentes aparecem nos gráficos\nElaboração: Alisson Soares')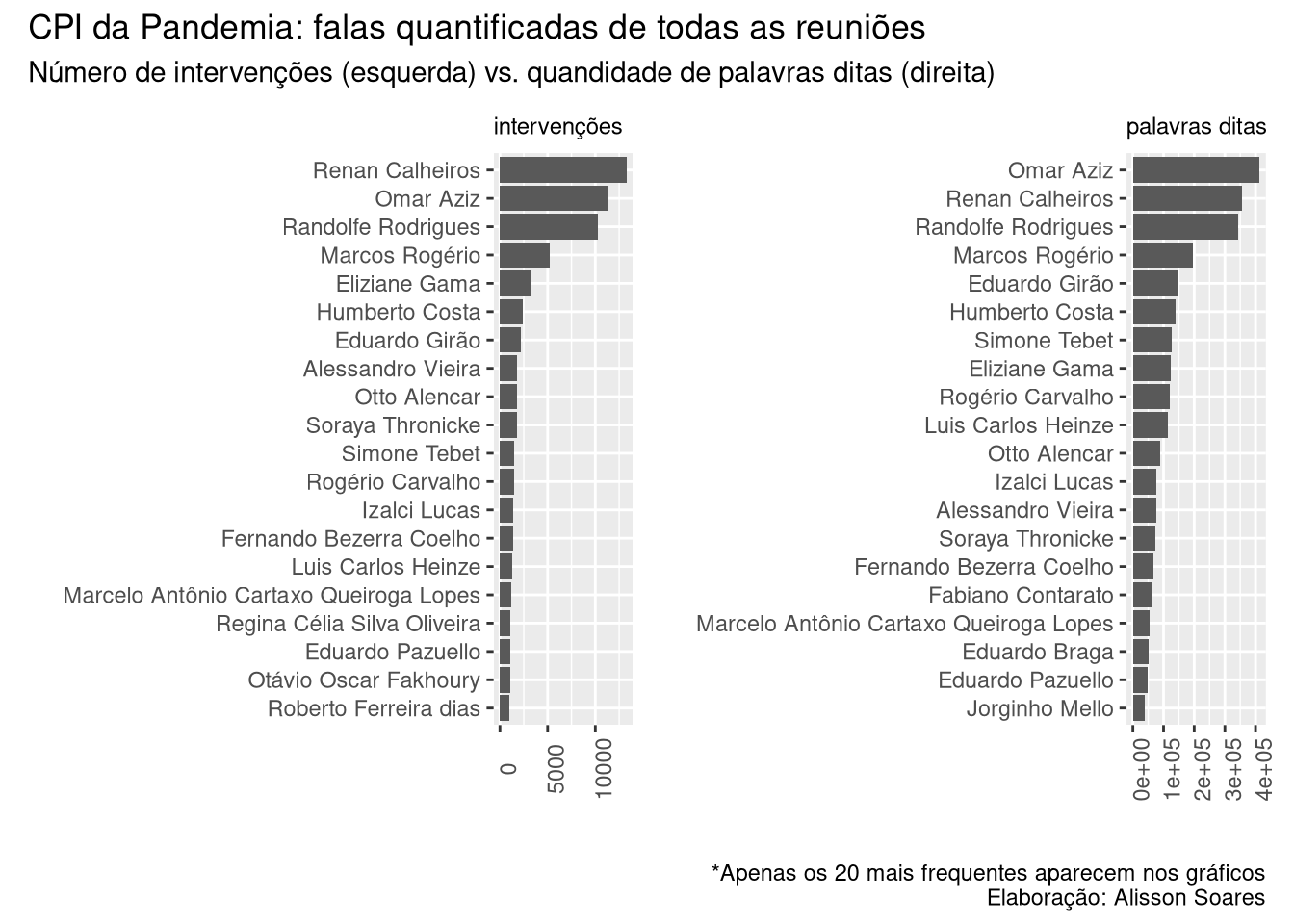
Vamos restringir inicialmente nossa base de dados para explorar melhor. Vamos começar somente com os senadores.
14.4.1 Opção 1: pegando apenas os senadores
Como somente os senadores que participaram possuem campo com partido e bloco parlamentar preenchido, uma opção para filtrarmos apenas os senadores seria excluindo as linhas cuja célula da coluna “BlocoParl” esteja vazia. <<
- O campo “funcao_blocoPar” possui, além da função e bloco parlamentar, possui também questões de ordem
- O campo “part” melhora a situação, mas podendo haver parlamentar sem partido, não resolve nosso problema
- o campo estado pode resolver nosso problema.
siglas <- c("AC", "AL", "AP", "AM", "BA", "CE", "DF", "ES", "GO", "MA", "MT", "MS", "MG", "PA", "PB", "PR", "PE", "PI", "RJ", "RN", "RS", "RO", "RR", "SC", "SP", "SE", "TO")
DFsenadores <- NotasTaq %>%
#filter(siglas %in% estado)
filter(estado %in% siglas)
DFsenadores
## # A tibble: 67,220 × 9
## reuniao data nome funcao_blocoPar BlocoParl partido estado complemento
## <dbl> <date> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 1 2021-04-27 Otto… PRESIDENTE (Otto Al… PSD BA "Fala da P…
## 2 1 2021-04-27 Ciro… (Bloco Parlame… Bloco Pa… PP PI "Para ques…
## 3 1 2021-04-27 Otto… PRESIDENTE (Otto Al… PSD BA ""
## 4 1 2021-04-27 Ciro… (Bloco Parlame… Bloco Pa… PP PI ""
## 5 1 2021-04-27 Otto… PRESIDENTE (Otto Al… PSD BA ""
## 6 1 2021-04-27 Ciro… (Bloco Parlame… Bloco Pa… PP PI ""
## 7 1 2021-04-27 Otto… PRESIDENTE (Otto Al… PSD BA ""
## 8 1 2021-04-27 Ciro… (Bloco Parlame… Bloco Pa… PP PI ""
## 9 1 2021-04-27 Otto… PRESIDENTE (Otto Al… PSD BA ""
## 10 1 2021-04-27 Ciro… (Bloco Parlame… Bloco Pa… PP PI ""
## # … with 67,210 more rows, and 1 more variable: fala <chr>
unique(DFsenadores$nome)
## [1] "Otto Alencar" "Ciro Nogueira"
## [3] "Jorginho Mello" "Izalci Lucas"
## [5] "Alessandro Vieira" "Eduardo Braga"
## [7] "Eduardo Girão" "Marcos Rogério"
## [9] "Omar Aziz" "Humberto Costa"
## [11] "Rogério Carvalho" "Weverton"
## [13] "Eliziane Gama" "Randolfe Rodrigues"
## [15] "Paulo Rocha" "Flávio Bolsonaro"
## [17] "Renan Calheiros" "Fernando Bezerra Coelho"
## [19] "Luis Carlos Heinze" "Angelo Coronel"
## [21] "Marcos do Val" "Simone Tebet"
## [23] "Leila Barros" "Tasso Jereissati"
## [25] "Zenaide Maia" "Fabiano Contarato"
## [27] "Vanderlan Cardoso" "Telmário Mota"
## [29] "Soraya Thronicke" "Jean Paul Prates"
## [31] "Mara Gabrilli" "Reguffe"
## [33] "Mecias de Jesus" "Roberto Rocha"
## [35] "Kátia Abreu" "Daniella Ribeiro"
## [37] "Jorge Kajuru" "Carlos Portinho"
## [39] "Styvenson Valentim" "Nelsinho Trad"
## [41] "Giordano" "Osmar Terra"
## [43] "Luis Miranda" "Rodrigo Cunha"
## [45] "Eliane Nogueira" "Reinhold Stephanes Junior"
## [47] "Ricardo Barros" "Rose de Freitas"
## [49] "Daniel Freitas" "Bia Kicis"No entanto, esta opção captou também os deputados que lá falaram, como Luis Miranda e Bia Kicis.
14.4.2 Opção 2: Somente senadores, a partir do site do Senado
Vamos pegar os nomes dos senadores no site do senado
library(rvest)
pagina_senadores <- rvest::read_html(url("https://www25.senado.leg.br/web/senadores/em-exercicio/"))
senadores <- pagina_senadores %>%
html_elements("#senadoresemexercicio-tabela-senadores a") %>%
html_text()
#html_attr("name")
head(senadores, 20)
## [1] "" "Mailza Gomes" "Marcio Bittar"
## [4] "Sérgio Petecão" "" "Fernando Collor"
## [7] "Renan Calheiros" "Rodrigo Cunha" ""
## [10] "Eduardo Braga" "Omar Aziz" "Plínio Valério"
## [13] "" "Davi Alcolumbre" "Lucas Barreto"
## [16] "Randolfe Rodrigues" "" "Angelo Coronel"
## [19] "Jaques Wagner" "Otto Alencar"
# Vimos que há muitos elementos vazios no vetor. Vamos retirá-los com o comando:
senadores <- senadores[senadores!= ""]
senadores
## [1] "Mailza Gomes" "Marcio Bittar"
## [3] "Sérgio Petecão" "Fernando Collor"
## [5] "Renan Calheiros" "Rodrigo Cunha"
## [7] "Eduardo Braga" "Omar Aziz"
## [9] "Plínio Valério" "Davi Alcolumbre"
## [11] "Lucas Barreto" "Randolfe Rodrigues"
## [13] "Angelo Coronel" "Jaques Wagner"
## [15] "Otto Alencar" "Cid Gomes"
## [17] "Eduardo Girão" "Tasso Jereissati"
## [19] "Izalci Lucas" "Leila Barros"
## [21] "Reguffe" "Fabiano Contarato"
## [23] "Marcos do Val" "Rose de Freitas"
## [25] "Jorge Kajuru" "Luiz Carlos do Carmo"
## [27] "Vanderlan Cardoso" "Eliziane Gama"
## [29] "Roberto Rocha" "Weverton"
## [31] "Alexandre Silveira" "Carlos Viana"
## [33] "Rodrigo Pacheco" "Nelsinho Trad"
## [35] "Simone Tebet" "Soraya Thronicke"
## [37] "Carlos Fávaro" "Fabio Garcia"
## [39] "Wellington Fagundes" "Jader Barbalho"
## [41] "Paulo Rocha" "Zequinha Marinho"
## [43] "Daniella Ribeiro" "Nilda Gondim"
## [45] "Veneziano Vital do Rêgo" "Fernando Bezerra Coelho"
## [47] "Humberto Costa" "Jarbas Vasconcelos"
## [49] "Eliane Nogueira" "Elmano Férrer"
## [51] "Marcelo Castro" "Alvaro Dias"
## [53] "Flávio Arns" "Oriovisto Guimarães"
## [55] "Carlos Portinho" "Flávio Bolsonaro"
## [57] "Romário" "Jean Paul Prates"
## [59] "Styvenson Valentim" "Zenaide Maia"
## [61] "Acir Gurgacz" "Confúcio Moura"
## [63] "Marcos Rogério" "Chico Rodrigues"
## [65] "Mecias de Jesus" "Telmário Mota"
## [67] "Lasier Martins" "Luis Carlos Heinze"
## [69] "Paulo Paim" "Dário Berger"
## [71] "Esperidião Amin" "Jorginho Mello"
## [73] "Alessandro Vieira" "Maria do Carmo Alves"
## [75] "Rogério Carvalho" "Giordano"
## [77] "José Serra" "Mara Gabrilli"
## [79] "Eduardo Gomes" "Irajá"
## [81] "Kátia Abreu"De posse dos nomes dos senadores, vamos ver quais nomes no nosso dataframe da CPI tem intersecção com a lista de senadores. Lembrando, esta lista foi gerada pouco tempo depois da CPI, assim, dependendo de quanto tempo você for tentar reproduzir o exemplo, o link pode ter expirado ou a lista de senadores pode já ter mudado.
Já havíamos gerado um vetor com os nomes de todos que participaram da CPI: “participantes”. Vamos fazer a intersecção dos participantes da CPI com os senadores para pegar apenas os senadores que participaram da CPI.
senadoresNaCPI <- participantes[participantes %in% senadores]
senadoresNaCPI
## [1] "Otto Alencar" "Jorginho Mello"
## [3] "Izalci Lucas" "Alessandro Vieira"
## [5] "Eduardo Braga" "Eduardo Girão"
## [7] "Marcos Rogério" "Omar Aziz"
## [9] "Humberto Costa" "Rogério Carvalho"
## [11] "Weverton" "Eliziane Gama"
## [13] "Randolfe Rodrigues" "Paulo Rocha"
## [15] "Flávio Bolsonaro" "Renan Calheiros"
## [17] "Fernando Bezerra Coelho" "Luis Carlos Heinze"
## [19] "Angelo Coronel" "Marcos do Val"
## [21] "Simone Tebet" "Leila Barros"
## [23] "Tasso Jereissati" "Zenaide Maia"
## [25] "Fabiano Contarato" "Vanderlan Cardoso"
## [27] "Telmário Mota" "Soraya Thronicke"
## [29] "Jean Paul Prates" "Mara Gabrilli"
## [31] "Reguffe" "Mecias de Jesus"
## [33] "Roberto Rocha" "Kátia Abreu"
## [35] "Daniella Ribeiro" "Jorge Kajuru"
## [37] "Carlos Portinho" "Styvenson Valentim"
## [39] "Nelsinho Trad" "Giordano"
## [41] "Rodrigo Cunha" "Eliane Nogueira"
## [43] "Rose de Freitas"Tendo agora a lista dos senadores que participaram da CPI, vamos filtrar as falas somente destes.
senadoresdf <- NotasTaq %>%
filter(nome %in% senadoresNaCPI )
str(senadoresdf)
## tibble [65,733 × 9] (S3: tbl_df/tbl/data.frame)
## $ reuniao : num [1:65733] 1 1 1 1 1 1 1 1 1 1 ...
## $ data : Date[1:65733], format: "2021-04-27" "2021-04-27" ...
## $ nome : chr [1:65733] "Otto Alencar" "Otto Alencar" "Otto Alencar" "Otto Alencar" ...
## $ funcao_blocoPar: chr [1:65733] "PRESIDENTE" "PRESIDENTE" "PRESIDENTE" "PRESIDENTE" ...
## $ BlocoParl : chr [1:65733] "(Otto Alencar. PSD - BA. Fala da Presidência.)" "(Otto Alencar. PSD - BA)" "(Otto Alencar. PSD - BA)" "(Otto Alencar. PSD - BA)" ...
## $ partido : Named chr [1:65733] "PSD" "PSD" "PSD" "PSD" ...
## ..- attr(*, "names")= chr [1:65733] "PSD" "PSD" "PSD" "PSD" ...
## $ estado : chr [1:65733] "BA" "BA" "BA" "BA" ...
## $ complemento : chr [1:65733] "Fala da Presidência" "" "" "" ...
## $ fala : chr [1:65733] "Invocando a proteção de Deus, declaro aberta a sessão para eleição, já que temos quórum suficiente para a abert"| __truncated__ "Senador Ciro Nogueira, esta é uma Comissão Parlamentar de Inquérito, vossa_excelência sabe que não é temática. "| __truncated__ "Eu indeferi. Sou Presidente e posso indeferir. " "Por que vossa_excelência não questionou à época essa questão de ordem? " ...
# criando um DF das falas de cada senador todas reunidas
senadores_falasJuntas <- NT_falasJuntasCount %>%
filter(nome %in% senadoresNaCPI )
str(senadores_falasJuntas)
## tibble [43 × 3] (S3: tbl_df/tbl/data.frame)
## $ nome : chr [1:43] "Omar Aziz" "Renan Calheiros" "Randolfe Rodrigues" "Marcos Rogério" ...
## $ N_palavras: int [1:43] 412985 354471 342415 196613 146258 139681 126382 124373 120381 114942 ...
## $ falas : chr [1:43] "Como é que é? Peço só um minutinho, só um minutinho! senhor Presidente... Eu acho que vossa_excelência.. Nós "| __truncated__ "Quer dizer que há outros impedimentos a serem... Acredito não ser o caso de V.Exa., mas o Estado de Alagoas é "| __truncated__ "Presidente... Presidente, qual a ordem? Presidente, só para declinar a ordem, quem são? Agora é a Eliziane? "| __truncated__ "senhor Presidente, senhors. e senhor. Senadores, faço a presente questão de ordem, senhor Presidente, desde log"| __truncated__ ...E outro tibble apenas com quem não for senador
nao_senadores <- NotasTaq %>%
filter(BlocoParl == "")
nao_senadores
## # A tibble: 24,296 × 9
## reuniao data nome funcao_blocoPar BlocoParl partido estado complemento
## <dbl> <date> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 10 2021-05-20 Edua… "" "" "" "" ""
## 2 10 2021-05-20 Edua… "" "" "" "" ""
## 3 10 2021-05-20 Edua… "" "" "" "" ""
## 4 10 2021-05-20 Edua… "" "" "" "" ""
## 5 10 2021-05-20 Edua… "" "" "" "" ""
## 6 10 2021-05-20 Edua… "" "" "" "" ""
## 7 10 2021-05-20 Edua… "" "" "" "" ""
## 8 10 2021-05-20 Edua… "" "" "" "" ""
## 9 10 2021-05-20 Edua… "" "" "" "" ""
## 10 10 2021-05-20 Edua… "" "" "" "" ""
## # … with 24,286 more rows, and 1 more variable: fala <chr>
unique(nao_senadores$nome)
## [1] "Eduardo Pazuello"
## [2] "Mayra Pinheiro"
## [3] "Dimas Tadeu Covas"
## [4] "Nise Hitomi Yamaguchi"
## [5] "Luana Araújo"
## [6] "Marcelo Antônio Cartaxo Queiroga Lopes"
## [7] "Antônio Elcio Franco Filho"
## [8] "Natalia Pasternak"
## [9] "Cláudio Maierovitch"
## [10] "Marcellus José Barroso Campêlo"
## [11] "Marcellus Campelo"
## [12] "Wilson Witzel"
## [13] "Francisco Eduardo Cardoso Alves"
## [14] "Ricardo Ariel Zimerman"
## [15] "Osmar Terra"
## [16] "Jurema Werneck"
## [17] "Pedro Hallal"
## [18] "Luis Ricardo Fernandes Miranda"
## [19] "Fausto Vieira dos Santos Junior"
## [20] "Wagner Lima da Costa"
## [21] "Gina Moraes de Almeida"
## [22] "Carlos Roberto Wizard Martins"
## [23] "Alberto Zacharias Toron"
## [24] "Guilherme Cremonesi Caurin"
## [25] "Luiz Henrique Mandetta"
## [26] "Luiz Paulo Dominguetti Pereira"
## [27] "Flavio Correa de Moraes"
## [28] "Regina Célia Silva Oliveira"
## [29] "Pedro Henrique Medeiros de Araújo"
## [30] "Roberto Ferreira dias"
## [31] "Maria Jamile José"
## [32] "Francieli Fontana Sutile Tardetti Fantinato"
## [33] "Francieli Fontana Sutile Fantinato"
## [34] "Thiago Leônidas"
## [35] "William Amorim Santana"
## [36] "Emanuela Batista de Souza Medrades"
## [37] "Ticiano Figueiredo de Oliveira"
## [38] "Pedro Ivo Velloso"
## [39] "Cristiano Alberto Hossri Carvalho"
## [40] "Fábio Henrique Ming Martini"
## [41] "Amilton Gomes de Paula"
## [42] "Otávio de Queiroga"
## [43] "Marcelo Blanco da Costa"
## [44] "Marcelo Blanco"
## [45] "Eric Furtado Ferreira Borges"
## [46] "Nelson Luiz Sperle Teich"
## [47] "Airton Antonio Soligo"
## [48] "Emerson Paxá Pinto Oliveira"
## [49] "Helcio Bruno de Almeida"
## [50] "João Carlos Gonçalves Krakauer Maia"
## [51] "Jailton Batista"
## [52] "Ricardo Barros"
## [53] "Alexandre Figueiredo Costa Silva Marques"
## [54] "Eduardo de Vilhena Toledo"
## [55] "Túlio Silveira"
## [56] "Francisco Emerson Maximiano"
## [57] "Ticiano Figueiredo"
## [58] "Emanuel Ramalho Catori"
## [59] "Michel Saliba Oliveira"
## [60] "Roberto Pereira Ramos Júnior"
## [61] "Alexandre Queiroz"
## [62] "José Ricardo Santana"
## [63] "Marcelo Queiroga"
## [64] "Alan Diniz Moreira Guedes de Ornelas"
## [65] "Ivanildo Gonçalves da Silva"
## [66] "Francisco Araújo Filho"
## [67] "Cleber Lopes de Oliveira"
## [68] "Marcos Tolentino da Silva"
## [69] "Luciano Duarte Peres"
## [70] "Marconny Nunes Ribeiro Albernaz de Faria"
## [71] "Wagner de Campos Rosário"
## [72] "Pedro Benedito Batista Júnior"
## [73] "Aristides Zacarelli"
## [74] "Maria José Ferreira Pessoa"
## [75] "Vinicius Luiz Ferreira"
## [76] "Danilo Berndt Trento"
## [77] "Bruna Mendes dos Santos Morato"
## [78] "Antonio Barra Torres"
## [79] "Luciano Hang"
## [80] "Beno Brandão"
## [81] "Otávio Oscar Fakhoury"
## [82] "Antonio Manssur"
## [83] "Milena Ramos Câmara"
## [84] "Raimundo Nonato Brasil"
## [85] "Andreia da Silva Lima"
## [86] "Walter José Faiad de Moura"
## [87] "Paulo Roberto Vanderlei Rebello Filho"
## [88] "Walter Correa de Souza Neto"
## [89] "Tadeu Frederico de Andrade"
## [90] "Priscila Pamela Cesario dos Santos"
## [91] "Rosane Maria dos Santos Brandão"
## [92] "Mayra Pires Lima"
## [93] "Antonio Carlos Alves de Sá Costa"
## [94] "Giovanna Gomes Mendes da Silva"
## [95] "Katia Shirlene Castilho dos Santos"
## [96] "Márcio Antonio do Nascimento Silva"
## [97] "Elton da Silva Chaves"
## [98] "Fabio Wajngarten"
## [99] "Carlos Murillo"
## [100] "Ernesto Araújo"14.5 wordcloud - Nuvem de palavras
Vamos observar os assuntos mais frequentes ali através da frequência de palavras. Vamos ver, de forma geral, as palavras mais frequentes.
tudo <- paste(NotasTaq_falas.agrupadas$falas, collapse = " ")
# Cuidado, não rode o objeto "tudo", pelo seu tamanho pode tavar o R
# ao invés disso, confira sua estrutura para conferir se está ok
str(tudo)
## chr "senhor Presidente, acredito que, em função da decisão, eu não sou obrigado, mas estou aqui para dizer a verdade"| __truncated__
class(tudo)
## [1] "character"
typeof(tudo)
## [1] "character"
# vamos contar quantas palavras foram ditas no total
sapply(strsplit(tudo, " "), length)
## [1] 3243133
tudo.df <- as_tibble(tudo, falas = tudo)
# tudo.tokens <- tudo %>% tidytext::unnest_tokens(word, falas)
# tudo.tokens <- tidytext::unnest_tokens(tudo.df , falas)
tudo.tokens <- tudo.df %>%
tidytext::unnest_tokens(word, value)A função wordcloud do pacote wordcloud permite enviar o texto diretamente para processamento, mas esta opção não é indicada por não permitir pré-processamento e por ser muito, bastante, extremamente lenta com a quantidade de texto que temos aqui. (Eu descobri isto testando antes). Vamos contar os valores únicos no nosso vetor “tudo.tokens”
# contando todas as palavras
tudo.tokens %>% dplyr::count()
## # A tibble: 1 × 1
## n
## <int>
## 1 3094644
# contando termos repetidos na coluna "word"
# Isto é, gerar a tabela de frequência de termos.
tudo.freq <- tudo.tokens %>% dplyr::count(word, sort = TRUE)
# observando um pedaço
head(tudo.freq, 25)
## # A tibble: 25 × 2
## word n
## <chr> <int>
## 1 que 114479
## 2 o 104603
## 3 de 103579
## 4 a 102691
## 5 não 69265
## 6 e 64093
## 7 é 51666
## 8 eu 50458
## 9 da 43083
## 10 do 42760
## # … with 15 more rowsO que nos dá uma lista das palavras mais frequentes, porém bem pouco informativas do assunto. Vamos retirar as palavras vazias, ou stopwords.
Vamos montar nossa lista de stopwords.
Como testei anteriormente, vi palavras que faltaram em nossa listagem. Vamos acrescentá-las a esta listagem as stopwords já existente em stopwords(pt).
# # Novo vetor de stopwords
SW <- c(stopwords::stopwords('pt'), 'é', 'aqui', 'então', 'porque')
# retirando as stopwords
quase.tudo <- tudo.tokens$word[!(tudo.tokens$word) %in% SW]
# observando as palavras mais frequentes atuais, sem algumas stopwords
nrow(tudo.tokens)
## [1] 3094480
head(quase.tudo, 40)
## [1] "senhor" "presidente" "acredito" "função"
## [5] "decisão" "obrigado" "dizer" "verdade"
## [9] "gostaria" "usá" "los" "senhor"
## [13] "presidente" "primeiramente" "bom" "dia"
## [17] "todos" "gostaria" "iniciar" "fala"
## [21] "cumprimentando" "todos" "senadores" "senhors"
## [25] "senadoras" "desta" "comissão" "pessoa"
## [29] "senhor" "presidente" "omar" "aziz"
## [33] "eminente" "senador" "relator" "renan"
## [37] "calheiros" "senhors" "senadoras" "nome"
length(quase.tudo)
## [1] 1617183
quase.tudo <- as_tibble(quase.tudo )
tudo.freq <- quase.tudo %>% dplyr::count(value, sort = TRUE)
# Observando as palavras mais frequentes
head(tudo.freq$value, 40)
## [1] "senhor" "senador" "presidente" "saúde"
## [5] "gente" "vossa_excelência" "ministério" "fazer"
## [9] "cpi" "ser" "aí" "brasil"
## [13] "dia" "ter" "governo" "sobre"
## [17] "sim" "vou" "vacina" "ministro"
## [21] "todos" "pessoas" "pode" "relação"
## [25] "vai" "agora" "federal" "v"
## [29] "sa" "pra" "dizer" "comissão"
## [33] "momento" "lá" "empresa" "hoje"
## [37] "questão" "quero" "doutor" "queria"E agora gerando nossa nuvem de palavras
# pegando apenas as primeiras palavras
pre.wc <- tudo.freq[1:150,]
wordcloud::wordcloud(pre.wc$value,
# se o input para esta função contém as frequências de palavras, o item abaixo deve ser descomentado
pre.wc$n,
# vetor com dois termos indicado o espectro de tamanho das palavras
scale=c(3,.6),
# cores, do menos frequente ao mais frequente
colors = c("royalblue","blue", "darkblue", "black"))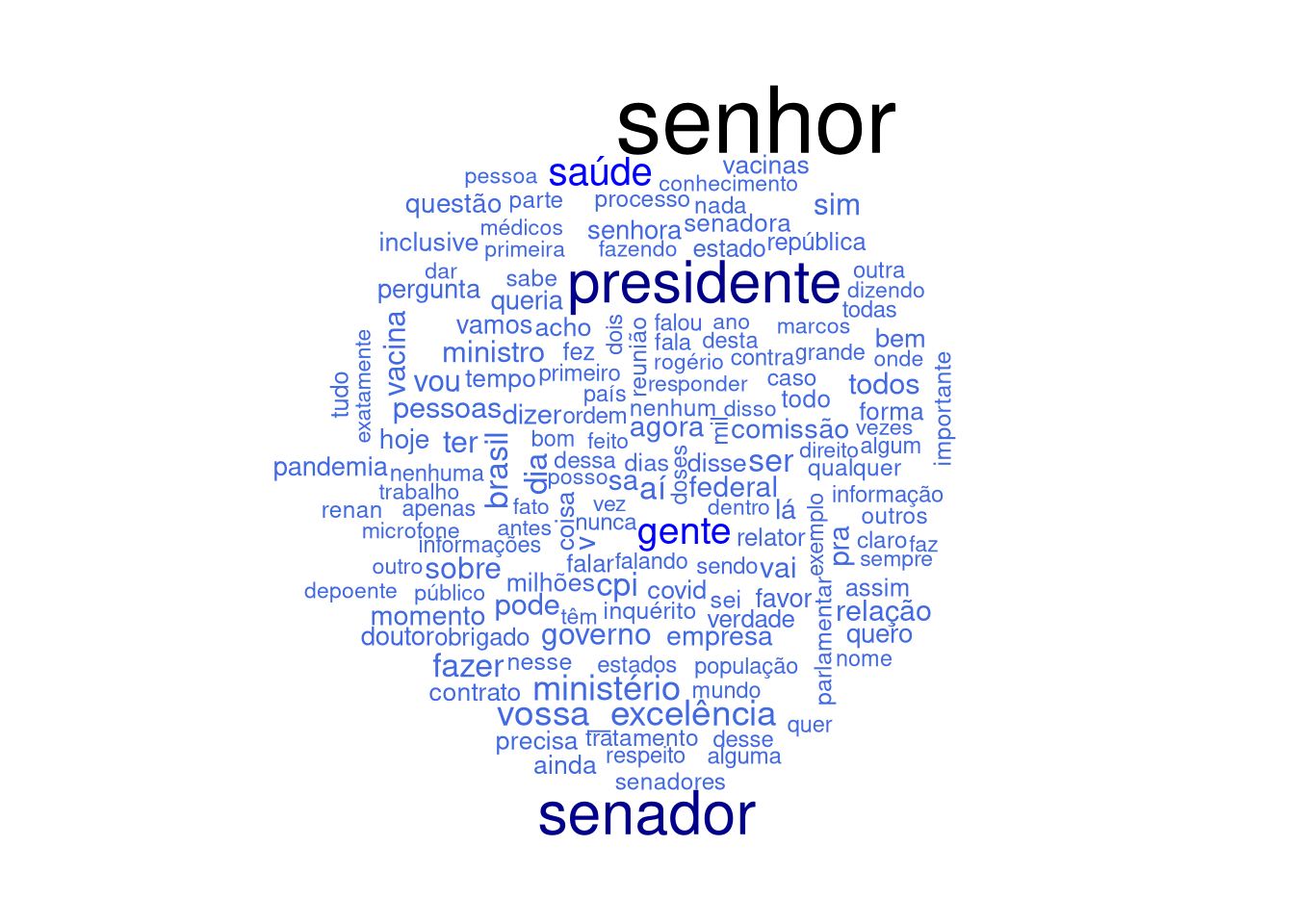
14.6 TF-IDF dos Senadores
# Observando novamente a estrutura do df que criamos só com os senadores
str(senadores_falasJuntas)
## tibble [43 × 3] (S3: tbl_df/tbl/data.frame)
## $ nome : chr [1:43] "Omar Aziz" "Renan Calheiros" "Randolfe Rodrigues" "Marcos Rogério" ...
## $ N_palavras: int [1:43] 412985 354471 342415 196613 146258 139681 126382 124373 120381 114942 ...
## $ falas : chr [1:43] "Como é que é? Peço só um minutinho, só um minutinho! senhor Presidente... Eu acho que vossa_excelência.. Nós "| __truncated__ "Quer dizer que há outros impedimentos a serem... Acredito não ser o caso de V.Exa., mas o Estado de Alagoas é "| __truncated__ "Presidente... Presidente, qual a ordem? Presidente, só para declinar a ordem, quem são? Agora é a Eliziane? "| __truncated__ "senhor Presidente, senhors. e senhor. Senadores, faço a presente questão de ordem, senhor Presidente, desde log"| __truncated__ ...
str(NT_falasJuntasCount)
## tibble [153 × 3] (S3: tbl_df/tbl/data.frame)
## $ nome : chr [1:153] "Omar Aziz" "Renan Calheiros" "Randolfe Rodrigues" "Marcos Rogério" ...
## $ N_palavras: int [1:153] 412985 354471 342415 196613 146258 139681 126382 124373 120381 114942 ...
## $ falas : chr [1:153] "Como é que é? Peço só um minutinho, só um minutinho! senhor Presidente... Eu acho que vossa_excelência.. Nós "| __truncated__ "Quer dizer que há outros impedimentos a serem... Acredito não ser o caso de V.Exa., mas o Estado de Alagoas é "| __truncated__ "Presidente... Presidente, qual a ordem? Presidente, só para declinar a ordem, quem são? Agora é a Eliziane? "| __truncated__ "senhor Presidente, senhors. e senhor. Senadores, faço a presente questão de ordem, senhor Presidente, desde log"| __truncated__ ...Vemos que temos 42 senadores que falaram na CPI, mas alguns deles falaram pouco (a Senadora Daniella Ribeiro, por exemplo, disse duas palavras). Vamos restringir este número
sen.tfidf <- senadores_falasJuntas |>
arrange(desc(N_palavras)) |> head(25) |>
# arrange(desc(N_palavras)) |> head(20)
tidytext::unnest_tokens(
output = 'word',
token = 'words',
input = falas,
strip_punct = T ) |>
dplyr::count(nome, word,
sort = TRUE) |> # contando os termos
tidytext::bind_tf_idf(word, nome, n) |>
arrange(desc(tf_idf))
# Se quiser conferir antes os nomes dos senadores selecionados
senadorTfIdf <- sen.tfidf$nome |> unique()
senadorTfIdf
## [1] "Reguffe" "Leila Barros"
## [3] "Izalci Lucas" "Soraya Thronicke"
## [5] "Jean Paul Prates" "Omar Aziz"
## [7] "Fabiano Contarato" "Luis Carlos Heinze"
## [9] "Otto Alencar" "Eliziane Gama"
## [11] "Zenaide Maia" "Simone Tebet"
## [13] "Eduardo Braga" "Marcos do Val"
## [15] "Randolfe Rodrigues" "Alessandro Vieira"
## [17] "Renan Calheiros" "Jorginho Mello"
## [19] "Tasso Jereissati" "Flávio Bolsonaro"
## [21] "Rogério Carvalho" "Eduardo Girão"
## [23] "Fernando Bezerra Coelho" "Marcos Rogério"
## [25] "Humberto Costa"
# Apenas as palavras de maior tf_idf de cada senador
# lembrando que já organizamos antes pelo tf-idf decrescente
sen.tfidf.top <- sen.tfidf |>
group_by(nome) |> slice_head(n = 7)Para não bagunçar o gráfico, vamos colocar um conjunto de nomes de cada vez
# Nomes de 1 a 9.
nomes <- senadorTfIdf[1:9]
# gerando o gráfico
sen.tfidf.top |>
filter(nome %in% nomes ) |>
ggplot(aes(reorder(word, tf_idf), tf_idf, fill = nome)) +
geom_bar(stat = "identity", alpha = .8, show.legend = FALSE) +
labs(title = "Palavras peculiares utilizadas",
subtitle = "tf-idf da fala dos senadores",
x = NULL, y = "tf-idf",
caption = "Fonte: Notas Taquigráficas CPI da Pandemia\nElaboração: Alisson Soares") +
facet_wrap(~nome, ncol = 3,
# as escalas nos diferentes gráficos não terão a mesma proporção
scales = "free") +
coord_flip()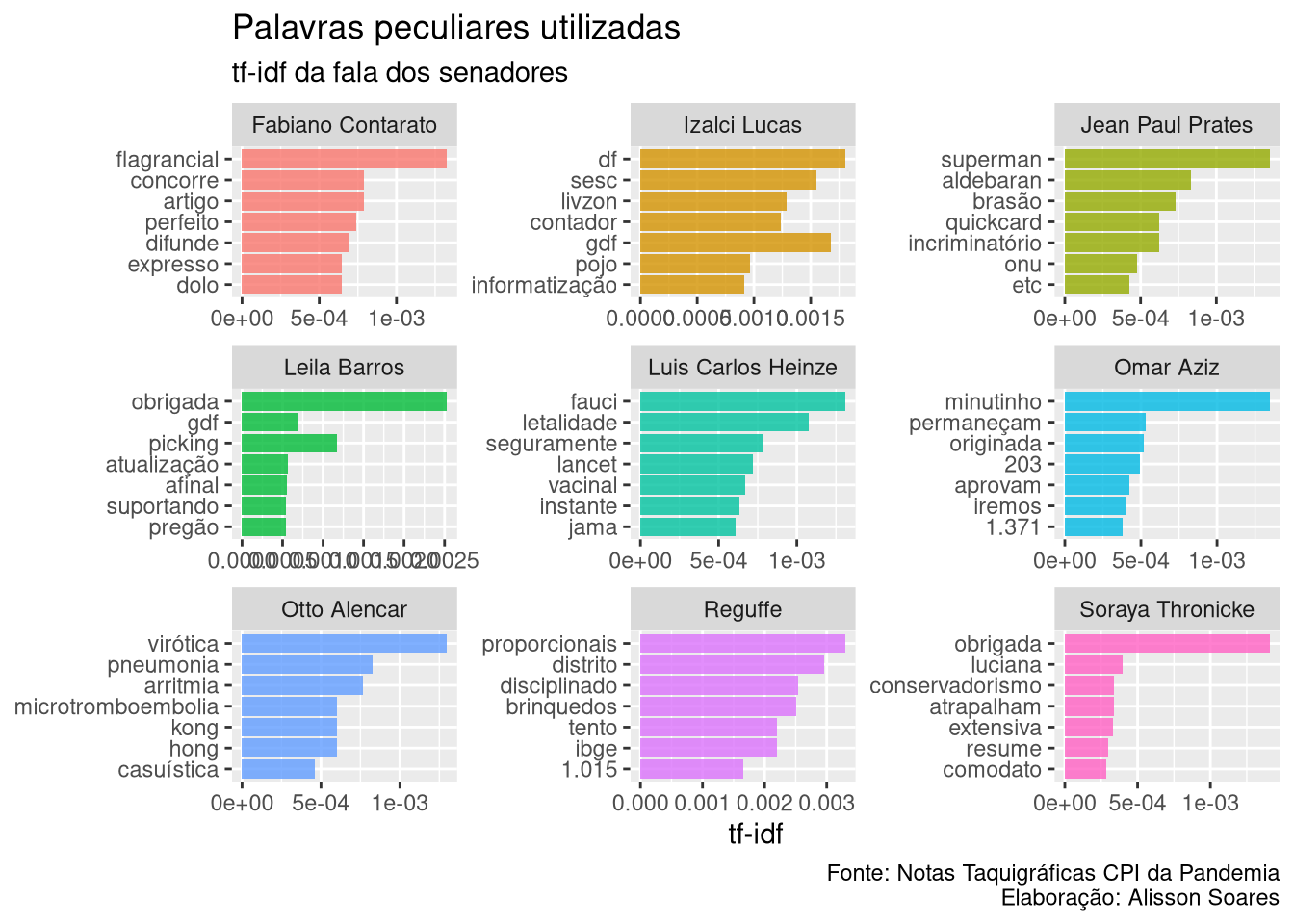
14.7 Dicionário
A conversão em matrizes e dessa para DTM é um passo intermediário crucial em diversas abordagens de análise textual, como TF-IDF e Topic Modeling.
Vamos gerar uma métrica de conceitos a partir de de dicionários de termos. Para cada conceito, escolhi um conjunto de palavras. As categorias como as palavras destas foram escolhidas de modo rápido, não sistemático. O vetor de vacinas foi comentado pois rodei previamente, os termos relacionados a vacina predominavam em todos os casos.
library(quanteda)
cpi.corpus <- corpus(NT_falasJuntasCount, docid_field = "nome", text_field = "falas")
# Criando um Document Term Matrix
# o processo abaixo demora um pouco
cpi.dfm <- tokens(cpi.corpus, remove_punct = TRUE) %>%
dfm() %>%
dfm_remove(pattern = SW )
# utilizando a lista de stopwords que criamos anteriormente
#tokens_select(pattern = SW, selection = "remove")
dict <- dictionary(list(
tratPre = c("cloroquina", "ivermectina", "azitromicina", "Kit", "precoce", "ozônio"),
tratPre.defensores = c("Raoult", "Zelenko", "Yamagushi", "Zebalos", "Wong", "Zanotto"),
# vacinas = c("vacinas?", "CoronaVac", "Sinopharm", "CanSino", "Butantan", "AstraZeneca", "Oxford", "Comirnaty", "Bharat", "BioTech", "BioNTech", "Pfizer", "Janss?en", "Johnson", "Spikevax", "Moderna", "Sputnik", "Gamaleya"),
corrupcao = c("corrup.*", "propin.*", "superfatur.*", "prevaric.*")))
# rodando nosso dicionário
dict_dtm <- dfm_lookup(cpi.dfm,
dictionary = dict,
valuetype = "regex",
nomatch = "_unmatched")
# nomatch = "semCorrespondencia")
# supondo que nosso dicionário seja minimamente bom
# vendo o quanto senadores abordaram certos temas
dict_dtm[5:10,]
## Document-feature matrix of: 6 documents, 4 features (8.33% sparse) and 1 docvar.
## features
## docs tratPre tratPre.defensores corrupcao _unmatched
## Eduardo Girão 165 0 159 61698
## Humberto Costa 272 11 60 57039
## Simone Tebet 54 0 125 51548
## Eliziane Gama 141 6 45 49397
## Rogério Carvalho 188 7 95 50114
## Luis Carlos Heinze 357 62 33 49666Gerando um gráfico com o ggplot
# vamos renomear os labels com os seguintes rótulos
rotulos <- c( "Corrupção", "Trat. Precoce", "Defensores trat. precoce")
# retirar a ultima coluna que não nos é útil
dict.df <- convert(dict_dtm[1:15,-5], to = "data.frame") %>%
tidyr::pivot_longer(.,
cols = names(dict),
values_to = "Valores")
ggplot(dict.df, aes(x = name, y = Valores, fill = name ) ) +
geom_col() +
labs(title = "Dicionário/conceito", x = NULL, y = NULL,
caption = "Observação: Cada pessoa está em uma escala diferente.\nElaboração: Alisson Soares",
fill = "Temáticas:"
) +
theme(legend.position="bottom",
text = element_text("Temáticas:")) +
# Mudando os nomes das variáveis na legenda
scale_fill_discrete(labels = rotulos) +
# Retirar os rótulos
scale_x_discrete(labels = NULL) +
facet_wrap(~doc_id, ncol = 3, scales = "free") +
# rotacionando o gráfico
coord_flip()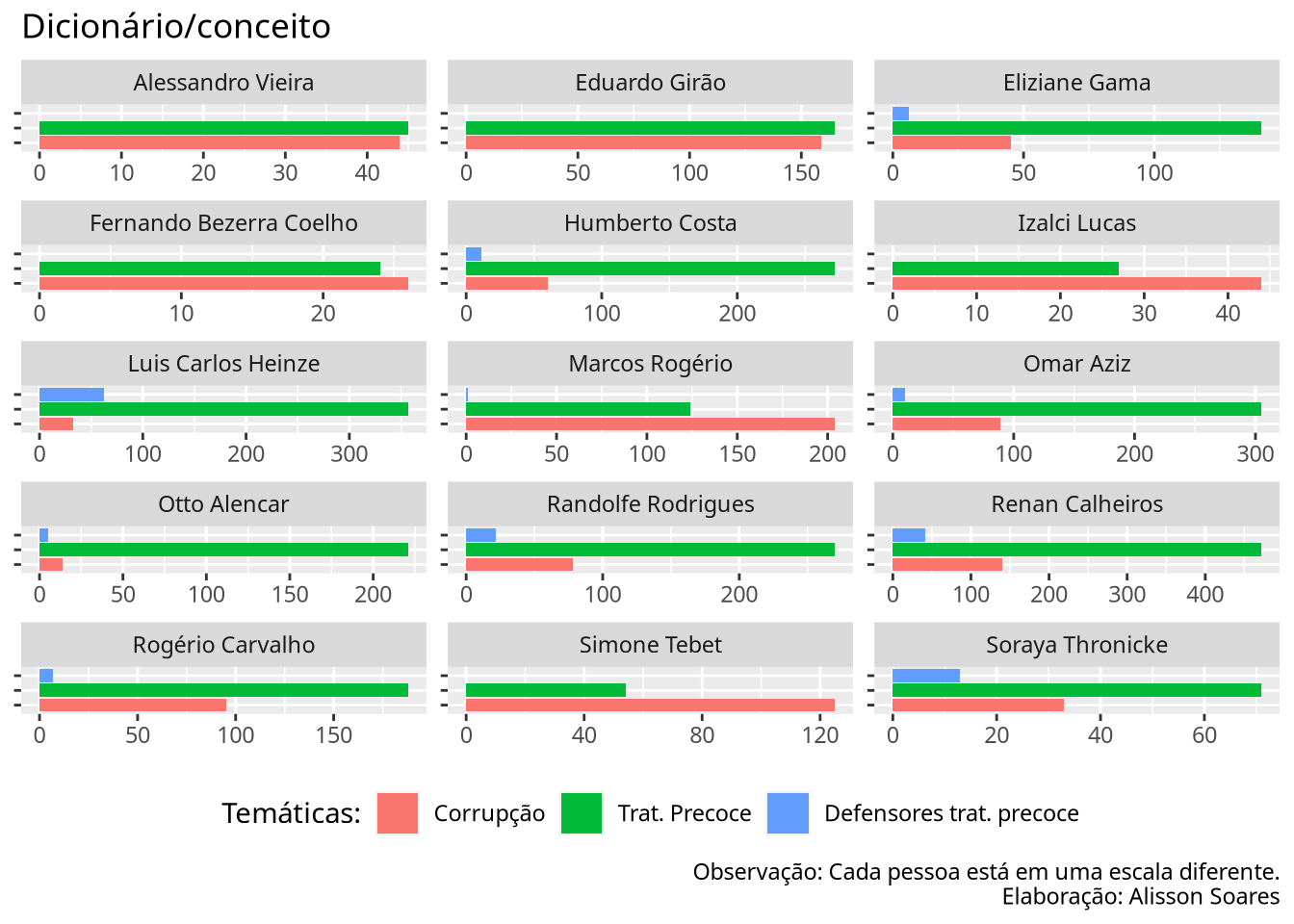
14.8 Modelagem de tópicos
A modelagem de tópicos pode demorar, dependendo das configurações de sua máquina e do tamanho do seu corpus a ser processado.
A função pryr::object_size(par_dtm) nos retornou que nosso objeto possui 7,6 Mb de tamanho, ou 7.3 Mb de tamanho sem as stopwords.
Usando a função system.time(funcao) é possível medir o tempo gasto por determinada tarefa.
Assim, um computador i5 com 8Gb de Ram demorou 662.695 segundos - cerca de 11 minutos - para rodar esta modelagem de tópicos de um arquivo de 7,6 Mb.
library(topicmodels)
texts <- corpus_reshape(cpi.corpus, to = "paragraphs")
#par_dtm <- dfm(texts, stem = TRUE,
# create a document-term matrix
# remove_punct = TRUE,
# remove = stopwords("english")
par_dtm <- dfm_trim(cpi.dfm, min_count = 5)
# remove rare terms
par_dtm <- convert(par_dtm, to = "topicmodels") # convert to topicmodels format
set.seed(1)
valor_k <- 7
lda_model <- topicmodels::LDA(par_dtm, method = "Gibbs", k = valor_k)
# vendo nossa modelagem de tópicos, 5 primeiras linhas
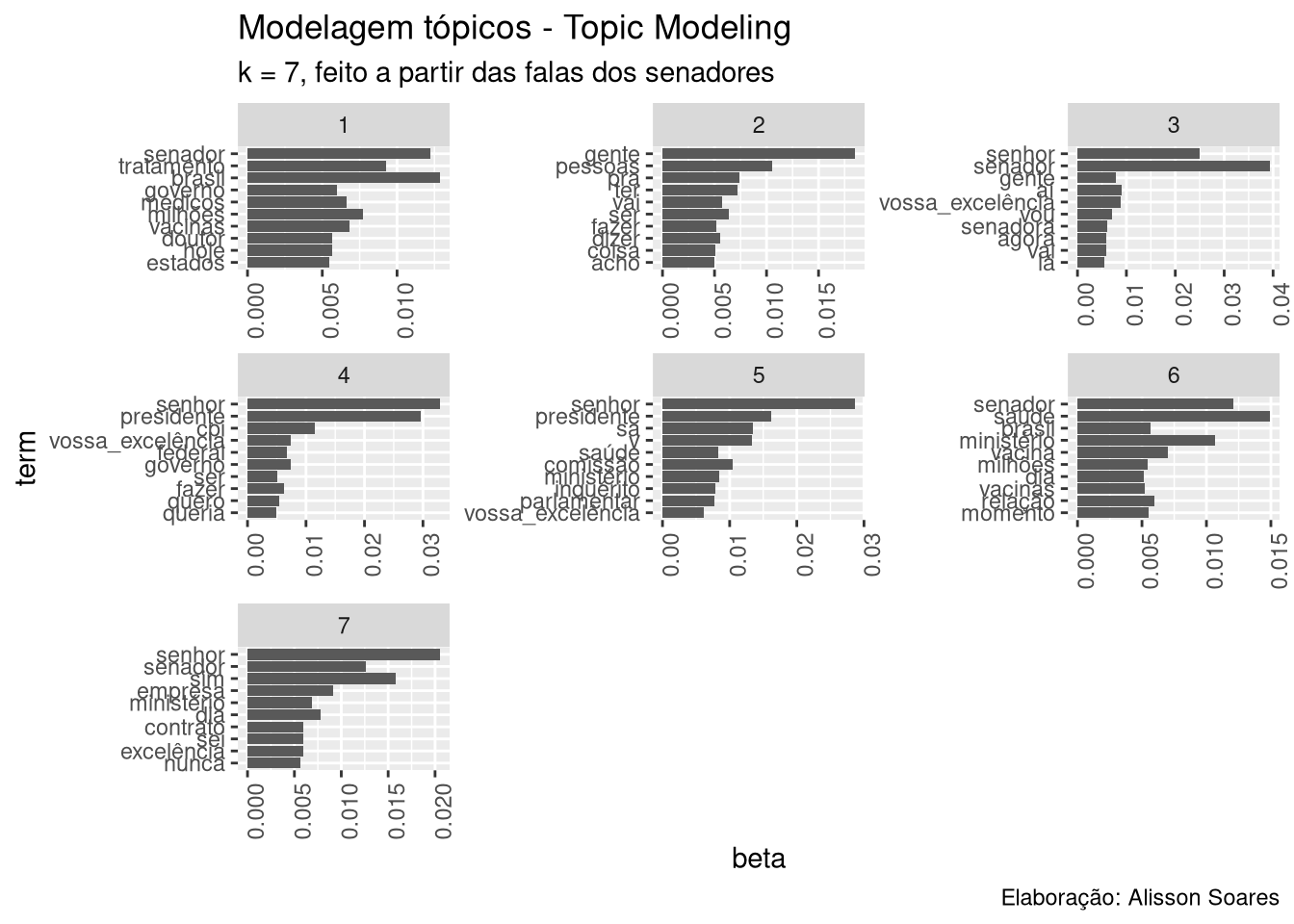
terms(lda_model, 5)
## Topic 1 Topic 2 Topic 3 Topic 4 Topic 5
## [1,] "brasil" "gente" "senador" "senhor" "senhor"
## [2,] "senador" "pessoas" "senhor" "presidente" "presidente"
## [3,] "tratamento" "pra" "aí" "cpi" "sa"
## [4,] "milhões" "ter" "vossa_excelência" "governo" "v"
## [5,] "vacinas" "ser" "gente" "vossa_excelência" "comissão"
## Topic 6 Topic 7
## [1,] "saúde" "senhor"
## [2,] "senador" "sim"
## [3,] "ministério" "senador"
## [4,] "vacina" "empresa"
## [5,] "relação" "dia"Vamos visualizar o topic modeling com o ggplot:
# convertendo para o formato tidy
topicos <- tidytext::tidy(lda_model, matrix = "beta")
termos_p_topico <- 10
top_termos <- topicos %>%
group_by(topic) %>%
top_n(termos_p_topico, beta) %>%
ungroup() %>%
arrange(topic, -beta)
# top_n() doesn't handle ties -__- so just take top 10 manually
top_termos <- top_termos %>%
group_by(topic) %>%
slice(1:termos_p_topico) %>%
ungroup()
top_termos$topic <- factor(top_termos$topic)
top_termos %>%
mutate(term = reorder(term, beta)) %>%
ggplot(aes(term, beta)) +
geom_bar(stat = "identity") +
facet_wrap(~ topic, scales = "free") +
theme(axis.text.x = element_text(angle = 90, hjust = 1)) +
coord_flip() +
labs(title = "Modelagem tópicos - Topic Modeling",
subtitle = paste0("k = ", valor_k, ", feito a partir das falas dos senadores"),
caption = "Elaboração: Alisson Soares")